堕天使の煉獄
2017-09
11
21:29:49
そんなもんだよな……
「ComicSoon」
漫画発売日リスト取得と登録作家名、作品名で一括検索ツール。
http://www.rengoku.sakura.ne.jp/program/software/comicsoon/index.html
ver 2.1.0 公開。
ローカルにある過去データから一括検索する機能追加~
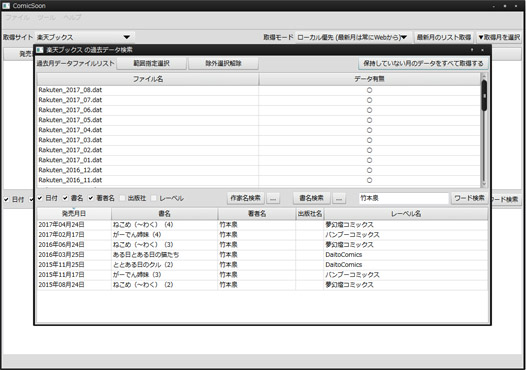
あんまし一括で過去データぶっこぬきしちゃうと、情報サイトのほうでなんか対策とかされそうなのでどうなのかなーとペンディングにしていた機能なんですが。
やっぱ某氏の言うようにように欲しい機能ではあるので、とりあえず試しに追加してみたり。
デバッグビルド中はくっそ重くてどうなんだコレと思ってたのですが、リリースビルドにすると、3年分のデータを数10件の作家名で検索かけても、数秒で終わる……。メチャ軽い。
そんでちょこちょこ試してたらばある事に気づく。
週間連載の作家さんの結果と、月刊連載もしくは不定期連載な作家さんの検索結果が如実に差が出るのまで見えて来ちゃうんだなとかw
情報サイトにもともと三年分しかないので過去三年分しか取れないにしても、月刊ペースの作家さんだと、せいぜい3~4冊ぐらい。
週刊だと普通に10冊ぐらい出てくるんですよね。やっぱ週刊ペースってすげぇ生産ペースだよなと。週間連載が出来る漫画家さんは超人なのだ(コミックマスターJより)
ついでにもう一ネタ
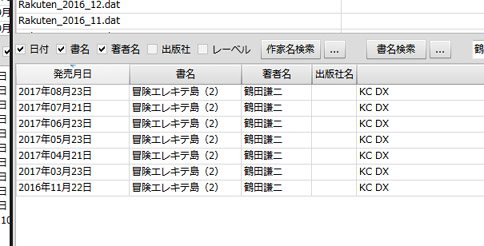
ちょっとまえにも触れたネタだけど。
鶴田謙二氏の冒険エレキテ島2巻、なんか毎月のようにリストに載ってるなーというので、過去データからの検索にかけてみるとこんな感じになってたのねと。
最初は2016年11月22日でそのあとは2017年03月23日からずっと毎月発売日リストにw
ここ最近は担当者が意地になってるのか、プレッシャーかける為に毎月載せてるんじゃないかと邪推w
PGネタとしては、以前から上手く行かない処理があって。
今回のでもつかっているのだけども、長い時間がかかる処理の場合、別スレッドで実行するみたいな処理で、処理中に中断のやり方がよくわからない。
中断するだけならできるんだけど、そのあとスレッドの終了処理タイミングと、実行もとのオブジェクトのデストラクタのタイミングとかでぶち落ちるんですよね。
「中断しますか?」みたいなダイアログだすと、なんでか中断指示だしたスレッドが動き続けて、ダイアログ閉じる前にスレッドの中でやってた処理が終わって処理終了時に実行もとのオブジェクトにシグナルで閉じる指示とか出してるもんだから、これもなんかダイアログ閉じた瞬間に落ちる~。
どうもダイアログもまた別のスレッドで処理してるので、その辺でなんかおかしな事になってるっぽい。
とりあえず中止かの質問ダイアログ出すの止めて進捗のプログレスバーだしてるダイアログのXボタンおしたら、ぶつっと確認無しで終了にしてアレコレやったりしたら、とりあえず落ちないで処理の終了は出来る様になったんですが。
いまいちスマートでない感じに。
この辺あんま情報ない&あっても英語の情報ばかりでこまるぅ。
あとはなんか最近のverのQtのデバッグビルドはなんかおかしい。
異様に遅くなったのもあるけど、今回のツールの場合、Webからファイルをダウンロードするとき、開始するまでにえらく待ち時間があるのと、DL中の現在読み込んだサイズと、全体のサイズてのがシグナルでおくられてくるのだけども、デバッグビルドだとなぜかずっと全体のサイズがつねに-1。
なんかデバッグビルドだとまともに動いてるのかのチェックすらままならなくなってきてるぅ。これほんとどうにかならんのか……。
も一つのほうのゲームPGのほうでは。
とりあえず試しに文字コードutf-8統一路線で進めてみようとおもったのだけども。
utf-8の文字列に対して文字数でsubstr出来るのとかちまちま作り出したところで、やっぱutf-8は文字列操作には向いてないんだなぁと。
ただ、現時点で、wchar_tは使わない、文字コードが環境依存で変わるっていう状況はやはりうざったい。てことで環境に依存しない文字コード固定で…・・っていう方向は間違ってはないとおもうのだけども。どうするのがスマートなのか。
そこでソースコード内のリテラルは全部u8""のutf-8で書く事にして。
で、独自のstring型を用意して、内部ではutf-16(std::wstring)で管理する感じにしてみることに。
独自のstring型はconst char*でもそのまま受け取れる(const char*はutf-8限定)
と、結局QStringのパクリみたいな感じの方向でいくことにw
しかしまあ、const char*で受け取るのも、暗黙でutf-8想定というところが気持ち悪いといえば気持ち悪い。char8_tがないからなぁ。
とはいえ、もしchar8_tあったとしたら何バイトになるのだろうか。
char = u8'a';
てのがわりと最近vc++でも有効になったのだけども。
これって1バイト文字の範囲のutf-8に限るんですよね。
char = u8'あ';
なんてのは当然無効。
んで、ちょうどutf-8対応のsubstr作ってたときに、コードの仕様とかまたみてたのだけど、どうも今まで結構古い仕様を参考にしていたようで、2003年11月からの新しい(つーても2003て随分前じゃん……)仕様だと、どうもutf-8の一文字の最大バイト数は4バイトになるらしい(ニコイチな文字とか特殊なのはべつとして)
以前はasciiコード互換の1バイト文字以外は3~6バイトっていう認識だったのですが。ただこの情報もほんとに最近のなのかよくわからんw
んでもutf-32とutf-8の関係って、utf-32をシリアライズしたものがutf-8という表現で解説してる所もあったりで。utf-32は4バイトじゃないですか。そうなると両者の差があんまり……。
英語圏の1バイト文字しか使わない人達にはutf-8ウマーなんだろうけどさ。
まあ、結局の所、欲しいのはchar8_tではなく、u8""の文字列をconst char*出受け取ると、中身がutf-8なのかどうなのか判らないというところで、これはutf-8デスよと規定するutf-8を扱う型が欲しいと言うだけなのですよね。
現状、utf-16とwchar_tがそんな感じの状況ですよね。
そのままではchar16_tはwchar_tに代入できないですし(内部のバイト列は同じでも別の型なので)。
それのutf-8版が欲しいだけなんですけどね……。
んでもutf-8のまいど文字の先頭位置(バイト単位)で取得するためには毎度先頭から走査するってのは実際組んでみるとうっとうしい仕様だなと。
文字単位で移動するイテレータとかそんなんも作ってみたりとか、一括で文字数とバイト数の対応のリストを作ってからアレコレするみたいな方向とかいろいろ試してみたけど……
普通にutf-16とかに変換しちゃったほうが楽だねコレ。という結論に達したw
utf-8だとstd::regexもダメ臭いし(実際には単なるバイナリ比較になってしまうので、途中の多バイト文字の中のasciiコードにマッチしてしまう)
std::regexで分割する(htmlタグ風のパーサーとか使う時とか)時はサロゲートペアチェックしてのutf-16かutf-32に変換してから……って感じになるのでしょうか。
以前組んだ奴はさろげーとぺあってなんですか? って感じで目線をそらす感じでutf-16のままつかってましたが、特に誤マッチとかもなく普通に使えてたりして。
デバッグビルドの時だけサロゲートペアチェックしてそこで問題無ければリリースビルドではサロゲートペアの処理しないutf-16固定というのも有りなのかなーと言う気も。
ほんと文字コード回りってめんどくさい。
漫画発売日リスト取得と登録作家名、作品名で一括検索ツール。
http://www.rengoku.sakura.ne.jp/program/software/comicsoon/index.html
ver 2.1.0 公開。
ローカルにある過去データから一括検索する機能追加~
あんまし一括で過去データぶっこぬきしちゃうと、情報サイトのほうでなんか対策とかされそうなのでどうなのかなーとペンディングにしていた機能なんですが。
やっぱ某氏の言うようにように欲しい機能ではあるので、とりあえず試しに追加してみたり。
デバッグビルド中はくっそ重くてどうなんだコレと思ってたのですが、リリースビルドにすると、3年分のデータを数10件の作家名で検索かけても、数秒で終わる……。メチャ軽い。
そんでちょこちょこ試してたらばある事に気づく。
週間連載の作家さんの結果と、月刊連載もしくは不定期連載な作家さんの検索結果が如実に差が出るのまで見えて来ちゃうんだなとかw
情報サイトにもともと三年分しかないので過去三年分しか取れないにしても、月刊ペースの作家さんだと、せいぜい3~4冊ぐらい。
週刊だと普通に10冊ぐらい出てくるんですよね。やっぱ週刊ペースってすげぇ生産ペースだよなと。週間連載が出来る漫画家さんは超人なのだ(コミックマスターJより)
ついでにもう一ネタ
ちょっとまえにも触れたネタだけど。
鶴田謙二氏の冒険エレキテ島2巻、なんか毎月のようにリストに載ってるなーというので、過去データからの検索にかけてみるとこんな感じになってたのねと。
最初は2016年11月22日でそのあとは2017年03月23日からずっと毎月発売日リストにw
ここ最近は担当者が意地になってるのか、プレッシャーかける為に毎月載せてるんじゃないかと邪推w
PGネタとしては、以前から上手く行かない処理があって。
今回のでもつかっているのだけども、長い時間がかかる処理の場合、別スレッドで実行するみたいな処理で、処理中に中断のやり方がよくわからない。
中断するだけならできるんだけど、そのあとスレッドの終了処理タイミングと、実行もとのオブジェクトのデストラクタのタイミングとかでぶち落ちるんですよね。
「中断しますか?」みたいなダイアログだすと、なんでか中断指示だしたスレッドが動き続けて、ダイアログ閉じる前にスレッドの中でやってた処理が終わって処理終了時に実行もとのオブジェクトにシグナルで閉じる指示とか出してるもんだから、これもなんかダイアログ閉じた瞬間に落ちる~。
どうもダイアログもまた別のスレッドで処理してるので、その辺でなんかおかしな事になってるっぽい。
とりあえず中止かの質問ダイアログ出すの止めて進捗のプログレスバーだしてるダイアログのXボタンおしたら、ぶつっと確認無しで終了にしてアレコレやったりしたら、とりあえず落ちないで処理の終了は出来る様になったんですが。
いまいちスマートでない感じに。
この辺あんま情報ない&あっても英語の情報ばかりでこまるぅ。
あとはなんか最近のverのQtのデバッグビルドはなんかおかしい。
異様に遅くなったのもあるけど、今回のツールの場合、Webからファイルをダウンロードするとき、開始するまでにえらく待ち時間があるのと、DL中の現在読み込んだサイズと、全体のサイズてのがシグナルでおくられてくるのだけども、デバッグビルドだとなぜかずっと全体のサイズがつねに-1。
なんかデバッグビルドだとまともに動いてるのかのチェックすらままならなくなってきてるぅ。これほんとどうにかならんのか……。
も一つのほうのゲームPGのほうでは。
とりあえず試しに文字コードutf-8統一路線で進めてみようとおもったのだけども。
utf-8の文字列に対して文字数でsubstr出来るのとかちまちま作り出したところで、やっぱutf-8は文字列操作には向いてないんだなぁと。
ただ、現時点で、wchar_tは使わない、文字コードが環境依存で変わるっていう状況はやはりうざったい。てことで環境に依存しない文字コード固定で…・・っていう方向は間違ってはないとおもうのだけども。どうするのがスマートなのか。
そこでソースコード内のリテラルは全部u8""のutf-8で書く事にして。
で、独自のstring型を用意して、内部ではutf-16(std::wstring)で管理する感じにしてみることに。
独自のstring型はconst char*でもそのまま受け取れる(const char*はutf-8限定)
と、結局QStringのパクリみたいな感じの方向でいくことにw
しかしまあ、const char*で受け取るのも、暗黙でutf-8想定というところが気持ち悪いといえば気持ち悪い。char8_tがないからなぁ。
とはいえ、もしchar8_tあったとしたら何バイトになるのだろうか。
char = u8'a';
てのがわりと最近vc++でも有効になったのだけども。
これって1バイト文字の範囲のutf-8に限るんですよね。
char = u8'あ';
なんてのは当然無効。
んで、ちょうどutf-8対応のsubstr作ってたときに、コードの仕様とかまたみてたのだけど、どうも今まで結構古い仕様を参考にしていたようで、2003年11月からの新しい(つーても2003て随分前じゃん……)仕様だと、どうもutf-8の一文字の最大バイト数は4バイトになるらしい(ニコイチな文字とか特殊なのはべつとして)
以前はasciiコード互換の1バイト文字以外は3~6バイトっていう認識だったのですが。ただこの情報もほんとに最近のなのかよくわからんw
んでもutf-32とutf-8の関係って、utf-32をシリアライズしたものがutf-8という表現で解説してる所もあったりで。utf-32は4バイトじゃないですか。そうなると両者の差があんまり……。
英語圏の1バイト文字しか使わない人達にはutf-8ウマーなんだろうけどさ。
まあ、結局の所、欲しいのはchar8_tではなく、u8""の文字列をconst char*出受け取ると、中身がutf-8なのかどうなのか判らないというところで、これはutf-8デスよと規定するutf-8を扱う型が欲しいと言うだけなのですよね。
現状、utf-16とwchar_tがそんな感じの状況ですよね。
そのままではchar16_tはwchar_tに代入できないですし(内部のバイト列は同じでも別の型なので)。
それのutf-8版が欲しいだけなんですけどね……。
んでもutf-8のまいど文字の先頭位置(バイト単位)で取得するためには毎度先頭から走査するってのは実際組んでみるとうっとうしい仕様だなと。
文字単位で移動するイテレータとかそんなんも作ってみたりとか、一括で文字数とバイト数の対応のリストを作ってからアレコレするみたいな方向とかいろいろ試してみたけど……
普通にutf-16とかに変換しちゃったほうが楽だねコレ。という結論に達したw
utf-8だとstd::regexもダメ臭いし(実際には単なるバイナリ比較になってしまうので、途中の多バイト文字の中のasciiコードにマッチしてしまう)
std::regexで分割する(htmlタグ風のパーサーとか使う時とか)時はサロゲートペアチェックしてのutf-16かutf-32に変換してから……って感じになるのでしょうか。
以前組んだ奴はさろげーとぺあってなんですか? って感じで目線をそらす感じでutf-16のままつかってましたが、特に誤マッチとかもなく普通に使えてたりして。
デバッグビルドの時だけサロゲートペアチェックしてそこで問題無ければリリースビルドではサロゲートペアの処理しないutf-16固定というのも有りなのかなーと言う気も。
ほんと文字コード回りってめんどくさい。
Sun
Mon
Tue
Wed
Thu
Fri
Sat
01
02
03
04
05
■
■
でもまた暑くなったりするんだろうな
06
07
08
09
10
■
■
消されるわ
11
■
■
そんなもんだよな……
12
13
14
15
16
17
18
■
■
ある意味キモイ
[敬老の日]
[敬老の日]
19
20
21
22
23
[秋分の日]
24
25
26
27
■
■
もはや何処も信用が……
28
29
30
total:2207550 t:1279 y:485
■記事タイトル■
■年度別リスト■
2026年
2026年12月(0)2026年11月(0)
2026年10月(0)
2026年09月(0)
2026年08月(0)
2026年07月(0)
2026年06月(0)
2026年05月(0)
2026年04月(0)
2026年03月(1)
2026年02月(3)
2026年01月(3)
2025年
2025年12月(1)2025年11月(1)
2025年10月(2)
2025年09月(5)
2025年08月(3)
2025年07月(1)
2025年06月(2)
2025年05月(1)
2025年04月(2)
2025年03月(3)
2025年02月(8)
2025年01月(3)
2024年
2024年12月(1)2024年11月(2)
2024年10月(1)
2024年09月(2)
2024年08月(1)
2024年07月(1)
2024年06月(5)
2024年05月(2)
2024年04月(1)
2024年03月(6)
2024年02月(4)
2024年01月(3)
2023年
2023年12月(3)2023年11月(1)
2023年10月(2)
2023年09月(3)
2023年08月(3)
2023年07月(3)
2023年06月(7)
2023年05月(8)
2023年04月(2)
2023年03月(1)
2023年02月(2)
2023年01月(3)
2022年
2022年12月(4)2022年11月(3)
2022年10月(1)
2022年09月(3)
2022年08月(3)
2022年07月(2)
2022年06月(1)
2022年05月(3)
2022年04月(2)
2022年03月(2)
2022年02月(1)
2022年01月(6)
2021年
2021年12月(8)2021年11月(3)
2021年10月(4)
2021年09月(6)
2021年08月(2)
2021年07月(1)
2021年06月(3)
2021年05月(2)
2021年04月(2)
2021年03月(3)
2021年02月(1)
2021年01月(4)
2020年
2020年12月(3)2020年11月(7)
2020年10月(2)
2020年09月(3)
2020年08月(1)
2020年07月(3)
2020年06月(7)
2020年05月(5)
2020年04月(8)
2020年03月(4)
2020年02月(2)
2020年01月(4)
2019年
2019年12月(1)2019年11月(1)
2019年10月(2)
2019年09月(1)
2019年08月(3)
2019年07月(2)
2019年06月(2)
2019年05月(2)
2019年04月(4)
2019年03月(1)
2019年02月(7)
2019年01月(1)
2018年
2018年12月(1)2018年11月(1)
2018年10月(5)
2018年09月(1)
2018年08月(5)
2018年07月(1)
2018年06月(1)
2018年05月(1)
2018年04月(2)
2018年03月(2)
2018年02月(1)
2018年01月(1)
2017年
2017年12月(2)2017年11月(1)
2017年10月(2)
2017年09月(5)
2017年08月(8)
2017年07月(2)
2017年06月(1)
2017年05月(1)
2017年04月(3)
2017年03月(5)
2017年02月(7)
2017年01月(8)
2016年
2016年12月(7)2016年11月(2)
2016年10月(3)
2016年09月(7)
2016年08月(8)
2016年07月(10)
2016年06月(17)
2016年05月(6)
2016年04月(8)
2016年03月(10)
2016年02月(5)
2016年01月(10)
2015年
2015年12月(7)2015年11月(7)
2015年10月(13)
2015年09月(7)
2015年08月(7)
2015年07月(5)
2015年06月(4)
2015年05月(5)
2015年04月(2)
2015年03月(4)
2015年02月(1)
2015年01月(7)
2014年
2014年12月(12)2014年11月(8)
2014年10月(4)
2014年09月(6)
2014年08月(7)
2014年07月(4)
2014年06月(2)
2014年05月(5)
2014年04月(4)
2014年03月(8)
2014年02月(4)
2014年01月(8)
2013年
2013年12月(15)2013年11月(8)
2013年10月(3)
2013年09月(3)
2013年08月(8)
2013年07月(0)
2013年06月(0)
2013年05月(0)
2013年04月(0)
2013年03月(0)
2013年02月(0)
2013年01月(0)
■レス履歴■
■ファイル抽出■
■ワード検索■
堕天使の煉獄
https://rengoku.sakura.ne.jp
管理人
織田霧さくら(oda-x)
E-mail (■を@に)
oda-x■rengoku.sakura.ne.jp