堕天使の煉獄
2017-09
27
02:08:03
もはや何処も信用が……
騙し騙し使ってたけど、ついに我慢できなくなってマウス交換。
LOGICOOL オプティカルゲーミングマウス G100s
随分前に、ネット通販で一個500円送料無料セールやってたのでぽちったのですが。
いまアマゾンで見たら3980円とかで売ってるよおい。
購入時、一個500円ならいっそ5個ぐらい買っとくかとおもったものの、外れだったらアレだなと2個だけにしたのですが。
一個目二個目、共に2~3ヶ月でちょっとチャタりぎみ? 騙し騙しつかって半年目ぐらいになるとダブルクリックとかあたりがまともに動作しなくなって、ちょっともう我慢の限界!! って感じに。
んまあ一個500円で半年*2ならまあ価格対効果としては許容範囲内だけど。
しかしこれ3980円で買ってこれだったら酷すぎるだろ。
レビューみても左クリックの耐久性に問題ありのレビューいくつかでてるし。
とんだ地雷マウスだった模様。
ロジクールはまだ信頼性高いメーカーってイメージあったんですけども、なんかレビューみると、2016年あたりからサポートの対応が悪く、保証期間中無償交換とかいいつつ、ひと月ほど放置の例もあるとかで。
まあ、もともと500円で買ったやつなので、交換とかめんどくさいし使い捨てのつもりで買ったのでもう廃棄でいいやな感じなんですが。
でもさすがにあのロジクールなら一個一年ぐらいは持つだろうとおもってたのに
まさかどっちも半年しかもたないとは……。
HDDもそうだけど、まだ信頼性高いとおもわれる日立東芝系も中国製になったりして、何処のを買ったらいいのかもうわかんね。
で、いま交換した奴は、これまたちょっと前にHDD換装したときについでに買ったマウスで、さすがにg100sがたまたま地雷だったんだろうと、800円ぐらい(だったかな?)で売ってたLOGICOOL M100rに交換。
……なんかえらく感度が悪いな。
なんでか膝の上とか布っぽいところだとヌルヌル動くのに、マウスパッドの上だとえらく反応が悪い。なんだコレw
そもG100sが、コレとは逆の、布の上とかだと反応悪くて、それでしかたなくそれまで使ってなかったマウスパッド引っ張り出してきて使い始めたのですが。
今度はマウスパッド上だと反応悪くなるとか意味わかんなーい。
アマゾンのレビュー見てみたら、ぴかぴか光沢のある所や、白い物の上だと反応悪く無いですかコレ? みたいな書き込みが。
マウスパッドみたら、白い格子模様のグリッドのようなものが書かれてるマウスパッドなんですよね。 それでか? とマウスパッド裏返して黒のスポンジ地? なところにおいてみたらヌルヌル動くー。
なんだかなぁ。
とりあえずマウスに多機能は求めてないので、ちゃんと動いてちゃんと左右クリック、ホイールが反応してくれればそれでいいんですが……。
基本的な操作の部分だけに、ちゃんと動かないとストレスたまるぅ。
LOGICOOL オプティカルゲーミングマウス G100s
随分前に、ネット通販で一個500円送料無料セールやってたのでぽちったのですが。
いまアマゾンで見たら3980円とかで売ってるよおい。
購入時、一個500円ならいっそ5個ぐらい買っとくかとおもったものの、外れだったらアレだなと2個だけにしたのですが。
一個目二個目、共に2~3ヶ月でちょっとチャタりぎみ? 騙し騙しつかって半年目ぐらいになるとダブルクリックとかあたりがまともに動作しなくなって、ちょっともう我慢の限界!! って感じに。
んまあ一個500円で半年*2ならまあ価格対効果としては許容範囲内だけど。
しかしこれ3980円で買ってこれだったら酷すぎるだろ。
レビューみても左クリックの耐久性に問題ありのレビューいくつかでてるし。
とんだ地雷マウスだった模様。
ロジクールはまだ信頼性高いメーカーってイメージあったんですけども、なんかレビューみると、2016年あたりからサポートの対応が悪く、保証期間中無償交換とかいいつつ、ひと月ほど放置の例もあるとかで。
まあ、もともと500円で買ったやつなので、交換とかめんどくさいし使い捨てのつもりで買ったのでもう廃棄でいいやな感じなんですが。
でもさすがにあのロジクールなら一個一年ぐらいは持つだろうとおもってたのに
まさかどっちも半年しかもたないとは……。
HDDもそうだけど、まだ信頼性高いとおもわれる日立東芝系も中国製になったりして、何処のを買ったらいいのかもうわかんね。
で、いま交換した奴は、これまたちょっと前にHDD換装したときについでに買ったマウスで、さすがにg100sがたまたま地雷だったんだろうと、800円ぐらい(だったかな?)で売ってたLOGICOOL M100rに交換。
……なんかえらく感度が悪いな。
なんでか膝の上とか布っぽいところだとヌルヌル動くのに、マウスパッドの上だとえらく反応が悪い。なんだコレw
そもG100sが、コレとは逆の、布の上とかだと反応悪くて、それでしかたなくそれまで使ってなかったマウスパッド引っ張り出してきて使い始めたのですが。
今度はマウスパッド上だと反応悪くなるとか意味わかんなーい。
アマゾンのレビュー見てみたら、ぴかぴか光沢のある所や、白い物の上だと反応悪く無いですかコレ? みたいな書き込みが。
マウスパッドみたら、白い格子模様のグリッドのようなものが書かれてるマウスパッドなんですよね。 それでか? とマウスパッド裏返して黒のスポンジ地? なところにおいてみたらヌルヌル動くー。
なんだかなぁ。
とりあえずマウスに多機能は求めてないので、ちゃんと動いてちゃんと左右クリック、ホイールが反応してくれればそれでいいんですが……。
基本的な操作の部分だけに、ちゃんと動かないとストレスたまるぅ。
2017-09
18
01:54:22
ある意味キモイ
なんか風つよいなーとおもったら台風きてたのですね。
窓を閉め切ってると空気がよどむ~。
そんな感じで相変わらずちまちまPG。
DXライブラリ@vc++
文字回りをガリゴリ。
gDebug() << u8"utf-8出力";
gDebug() << L"utf-16(wchar_t)出力";
QtのqDebugと同じ感じの記法でデバッグ出力出来る様に<<をオーバーロードすれば独自クラスの中身も出力できるのも同じ。
windows環境にあわせてワイド文字でもutf8でもどっちでもそのまま出力指定出来るところがちょっと違う所。
でもなんだかキモイなこれw
基本的にはdxf::stringという独自文字クラスを用意して、const char*はutf-8前提でutf-8も受け取れる様にして内部ではutf-16(std::wstring)で持つ(utf-8は受け取ったところでutf-16に変換する)感じに。
毎度utf-8で受け取るとそのたびに変換するコスト掛かっちゃうけど、まあ微々たるものだろう。ループの中なんかならL""つかえば変換掛からないし、使い方次第ぽ?
とりあえずこれで_T("")を使わなくて済むようになるのは大きい。
_T("")ていちいち打つのめんどいんですよね。そんでもってQtとかにコード持ってくときにも邪魔になるし。TCHARとかの将来性もよくわからんwin固有の邪魔くさい型もつかわなくて済む用になったし。
個人的な精神的衛生上の問題 > utf-8→utf-16の変換コスト
です(ぉ
で、次にQString風のフォーマット書式系も使える用にしてみたり。
dxf::string test5 = dxf::string::format(u8"フォーマット書式 %d %s", 15, u8"文字");
dxf::string test6 = dxf::string(u8"フォーマット書式 %1 そのに%2 aa%3bb").arg(u8"挿入").arg(L"あいうえお").arg(u8"三個目");
dxf::string test7 = dxf::string(u8" %1 %3 %2 %4 ").arg(100).arg(25, 4, 10, u8'-').arg(128, 4, 16).arg((char)128, 0, 2);
結果:
------------------------------------------------
フォーマット書式 15 文字
フォーマット書式 挿入 そのにあいうえお aa三個目bb
100 0x0080 --25 0b10000000
------------------------------------------------
作ってみたところで、argの数値→文字あたりの書式指定方法回りがちょっと厳しいなと。
arg(T value, uint digits = 0, int base = 10, dxf::DxfChar fill = dxf::DxfChar('0'));
宣言部分はおおむねQStringのパクリなんですが、base = 10のとこ、2にすると2進数、8にすると8進数16にすると16進数になるのですが。
そも普通に8進数なんか使わない。
2進数と16進数はほぼデバッグ用途ですよね。
んでもって2進数は中身はstd::bitsetを使ってるので桁数指定は引数じゃ指定出来ないstd::bitset<size_t N>とテンプレートパラメータで指定するので、定数じゃないと指定出来ないのですよ。通常は桁数を決め打ちするか
constexpr int kbit = sizeof(T) * CHAR_BIT;
ostr << std::bitset<kbit>(value);
って感じで2進数表記にしたい値の入ってる変数の型からサイズを指定するパターンが普通だとおもわれ。
そうなると、もともとbase = 2を指定したときにはuint digitsは不要になるんですよね。(そして2進数表記はもとから型サイズありきで自分で桁数指定する意味ももともと薄い)
しかし他の所の指定はデフォルト値も使用したいところではあるし、引数のオーバーロードでの対応はいろいろと無理があるなーと言う感じに。
template<typename T, std::enable_if_t<std::is_integral<T>::value, nullptr_t> = nullptr>
arg_hex(T value, uint digits = 0, bool prefix=true);
template<typename T, std::enable_if_t<std::is_integral<T>::value, nullptr_t> = nullptr>
arg_bit(T value, bool prefix=true);
なんて感じで2進数と16進数だけ別関数にした方が良いんじゃ無かろうかとか。
そうすることで、元のargのみの時の場合だとどうしたもんかなと思ってたプレフィックス(0xとか0b)の付ける付けないの指定も個別で対応できるし、そもそも2進数と16進数はほぼデバッグ用途と考えれば別関数に別けるのもまあ有りなのかなとか。
あとちょっと嵌ったのが、T valueにboolが来た場合
bool b = true;
dxf::string(u8"真偽 = %1").arg(b);
みたいなので、"true" "false"に置き換わるようなのも欲しいかなとおもって追加してみたらば。
dxf::string(u8"%1 %2").arg(u8"あああ").arg(u8"いいい");
の結果まで
"true true"
になってしまったり。
あーc++ではたしか文字リテラルってboolに暗黙変換されるとかいうルールあったなーと。
arg(const char* str)
があればこっちのが優先されるのだけども
arg(const std::string& str)とか
arg(std::string_view sv)だと
オーバーロードの優先順位的にboolのが先に候補に挙がってしまうっぽい。
そんな感じで、オーバーロードや引数、デフォルト引数、その辺の兼ね合いで結構いろいろと試行錯誤を繰り返し中。
sprintf系のフォーマット書式もなんだかんだでうっとうしいし、QString風のargでくっつけてく形も、argの方でいろいろアレンジ出来る幅はあるものの、結構面倒なことになってるなとQStringのドキュメントみておもたり。
argのオーバーロード結構使ったことないパターン結構いっぱいあるぽ。
ドキュメントみて初めて知ったけど、置き換え用指定の%nのnてQStringだと1~99まで使えるのね。
漠然と1~9個の9個までとかなのかなとかおもてました。
んでもまあ、自前で作ってる方のはゲーム用のなので、あんまし機能とか付けすぎてもなと。基本ゲームPGの場合は実行速度の方が重要度高いので。
%1%3%2 とかなってるときにちゃんと%1の次は%2を置き換えて~とかいう順番も端折って、番号なんか飾りですよとばかりに、とにかく%+数字がヒットした順番に置換ってのでもいいかなーとかも考えたぐらいで。
置き換え文字が1文字だとその文字自体が使えなくなってしまうので、番号とセットって感じの措置はやっぱ必要か……。しかしそれはそれで番号の意味無いってのもなんだか気持ち悪いなぁ。
ということで現状、結局数字順でちゃんと置換する形にしましたが……。%%とか二つつづき限定とかもいろいろ考えたりはしたのですけど。
試しに書いてみると……。
dxf::string(u8"フォーマット書式 %% そのに%% aa%%bb").arg(u8"挿入").arg(L"あいうえお").arg(u8"三個目");
コレはコレで、何処に何番目のargの値が入るのかわかりにくいし、argの個数が全部でいくつなのかもわかりにくいか………やはり番号は必要ぽ。
んでもQtのQStringで触ってた時には、いちいち番号ふるの面倒っちゃ面倒だなーという気はしてたりして。だいたい頭から順番てのがデフォで結局頭から連番以外で使う事は殆どなかったりで。番号の順番かえて置換位置変えるなんてのは、ごく稀にやった記憶があるぐらいで。
むーん。
しかし、ここ数年で随分と文字回りも書き方がいろいろと変わったなと実感。
std::sting_viewはかなり汎用性が高くてもはや無くてはならないってぐらいになってるし。
でも値→文字あたりでいろいろと書式指定で変換しようと思うと、相変わらずstringstreamとかつかわなならんのはなぁ。
#include <charconv> // c++17
std::to_chars
std::from_chars
なるものがあるようなのだけど、まだVisualStudio15.3.4の段階ではまだ追加されていないぽ。
でもこれも
C++1z ロケール依存なし、フォーマット解析なしの高速な文字列・数値変換
ttp://faithandbrave.hateblo.jp/entry/2016/08/24/181540
0埋めとか一部の機能が無いので、完全にコレ一本で……とはならないぽ。
でもこれ自体はかなりパフォーマンス重視らしいので、はやく追加されて欲しいなぁ。
そんな感じでゲームPGといいつつ、画面は真っ黒のまま。
デバッグ出力で文字みてるだけの最近……。
窓を閉め切ってると空気がよどむ~。
そんな感じで相変わらずちまちまPG。
DXライブラリ@vc++
文字回りをガリゴリ。
gDebug() << u8"utf-8出力";
gDebug() << L"utf-16(wchar_t)出力";
QtのqDebugと同じ感じの記法でデバッグ出力出来る様に<<をオーバーロードすれば独自クラスの中身も出力できるのも同じ。
windows環境にあわせてワイド文字でもutf8でもどっちでもそのまま出力指定出来るところがちょっと違う所。
でもなんだかキモイなこれw
基本的にはdxf::stringという独自文字クラスを用意して、const char*はutf-8前提でutf-8も受け取れる様にして内部ではutf-16(std::wstring)で持つ(utf-8は受け取ったところでutf-16に変換する)感じに。
毎度utf-8で受け取るとそのたびに変換するコスト掛かっちゃうけど、まあ微々たるものだろう。ループの中なんかならL""つかえば変換掛からないし、使い方次第ぽ?
とりあえずこれで_T("")を使わなくて済むようになるのは大きい。
_T("")ていちいち打つのめんどいんですよね。そんでもってQtとかにコード持ってくときにも邪魔になるし。TCHARとかの将来性もよくわからんwin固有の邪魔くさい型もつかわなくて済む用になったし。
個人的な精神的衛生上の問題 > utf-8→utf-16の変換コスト
です(ぉ
で、次にQString風のフォーマット書式系も使える用にしてみたり。
dxf::string test5 = dxf::string::format(u8"フォーマット書式 %d %s", 15, u8"文字");
dxf::string test6 = dxf::string(u8"フォーマット書式 %1 そのに%2 aa%3bb").arg(u8"挿入").arg(L"あいうえお").arg(u8"三個目");
dxf::string test7 = dxf::string(u8" %1 %3 %2 %4 ").arg(100).arg(25, 4, 10, u8'-').arg(128, 4, 16).arg((char)128, 0, 2);
結果:
------------------------------------------------
フォーマット書式 15 文字
フォーマット書式 挿入 そのにあいうえお aa三個目bb
100 0x0080 --25 0b10000000
------------------------------------------------
作ってみたところで、argの数値→文字あたりの書式指定方法回りがちょっと厳しいなと。
arg(T value, uint digits = 0, int base = 10, dxf::DxfChar fill = dxf::DxfChar('0'));
宣言部分はおおむねQStringのパクリなんですが、base = 10のとこ、2にすると2進数、8にすると8進数16にすると16進数になるのですが。
そも普通に8進数なんか使わない。
2進数と16進数はほぼデバッグ用途ですよね。
んでもって2進数は中身はstd::bitsetを使ってるので桁数指定は引数じゃ指定出来ないstd::bitset<size_t N>とテンプレートパラメータで指定するので、定数じゃないと指定出来ないのですよ。通常は桁数を決め打ちするか
constexpr int kbit = sizeof(T) * CHAR_BIT;
ostr << std::bitset<kbit>(value);
って感じで2進数表記にしたい値の入ってる変数の型からサイズを指定するパターンが普通だとおもわれ。
そうなると、もともとbase = 2を指定したときにはuint digitsは不要になるんですよね。(そして2進数表記はもとから型サイズありきで自分で桁数指定する意味ももともと薄い)
しかし他の所の指定はデフォルト値も使用したいところではあるし、引数のオーバーロードでの対応はいろいろと無理があるなーと言う感じに。
template<typename T, std::enable_if_t<std::is_integral<T>::value, nullptr_t> = nullptr>
arg_hex(T value, uint digits = 0, bool prefix=true);
template<typename T, std::enable_if_t<std::is_integral<T>::value, nullptr_t> = nullptr>
arg_bit(T value, bool prefix=true);
なんて感じで2進数と16進数だけ別関数にした方が良いんじゃ無かろうかとか。
そうすることで、元のargのみの時の場合だとどうしたもんかなと思ってたプレフィックス(0xとか0b)の付ける付けないの指定も個別で対応できるし、そもそも2進数と16進数はほぼデバッグ用途と考えれば別関数に別けるのもまあ有りなのかなとか。
あとちょっと嵌ったのが、T valueにboolが来た場合
bool b = true;
dxf::string(u8"真偽 = %1").arg(b);
みたいなので、"true" "false"に置き換わるようなのも欲しいかなとおもって追加してみたらば。
dxf::string(u8"%1 %2").arg(u8"あああ").arg(u8"いいい");
の結果まで
"true true"
になってしまったり。
あーc++ではたしか文字リテラルってboolに暗黙変換されるとかいうルールあったなーと。
arg(const char* str)
があればこっちのが優先されるのだけども
arg(const std::string& str)とか
arg(std::string_view sv)だと
オーバーロードの優先順位的にboolのが先に候補に挙がってしまうっぽい。
そんな感じで、オーバーロードや引数、デフォルト引数、その辺の兼ね合いで結構いろいろと試行錯誤を繰り返し中。
sprintf系のフォーマット書式もなんだかんだでうっとうしいし、QString風のargでくっつけてく形も、argの方でいろいろアレンジ出来る幅はあるものの、結構面倒なことになってるなとQStringのドキュメントみておもたり。
argのオーバーロード結構使ったことないパターン結構いっぱいあるぽ。
ドキュメントみて初めて知ったけど、置き換え用指定の%nのnてQStringだと1~99まで使えるのね。
漠然と1~9個の9個までとかなのかなとかおもてました。
んでもまあ、自前で作ってる方のはゲーム用のなので、あんまし機能とか付けすぎてもなと。基本ゲームPGの場合は実行速度の方が重要度高いので。
%1%3%2 とかなってるときにちゃんと%1の次は%2を置き換えて~とかいう順番も端折って、番号なんか飾りですよとばかりに、とにかく%+数字がヒットした順番に置換ってのでもいいかなーとかも考えたぐらいで。
置き換え文字が1文字だとその文字自体が使えなくなってしまうので、番号とセットって感じの措置はやっぱ必要か……。しかしそれはそれで番号の意味無いってのもなんだか気持ち悪いなぁ。
ということで現状、結局数字順でちゃんと置換する形にしましたが……。%%とか二つつづき限定とかもいろいろ考えたりはしたのですけど。
試しに書いてみると……。
dxf::string(u8"フォーマット書式 %% そのに%% aa%%bb").arg(u8"挿入").arg(L"あいうえお").arg(u8"三個目");
コレはコレで、何処に何番目のargの値が入るのかわかりにくいし、argの個数が全部でいくつなのかもわかりにくいか………やはり番号は必要ぽ。
んでもQtのQStringで触ってた時には、いちいち番号ふるの面倒っちゃ面倒だなーという気はしてたりして。だいたい頭から順番てのがデフォで結局頭から連番以外で使う事は殆どなかったりで。番号の順番かえて置換位置変えるなんてのは、ごく稀にやった記憶があるぐらいで。
むーん。
しかし、ここ数年で随分と文字回りも書き方がいろいろと変わったなと実感。
std::sting_viewはかなり汎用性が高くてもはや無くてはならないってぐらいになってるし。
でも値→文字あたりでいろいろと書式指定で変換しようと思うと、相変わらずstringstreamとかつかわなならんのはなぁ。
#include <charconv> // c++17
std::to_chars
std::from_chars
なるものがあるようなのだけど、まだVisualStudio15.3.4の段階ではまだ追加されていないぽ。
でもこれも
C++1z ロケール依存なし、フォーマット解析なしの高速な文字列・数値変換
ttp://faithandbrave.hateblo.jp/entry/2016/08/24/181540
0埋めとか一部の機能が無いので、完全にコレ一本で……とはならないぽ。
でもこれ自体はかなりパフォーマンス重視らしいので、はやく追加されて欲しいなぁ。
そんな感じでゲームPGといいつつ、画面は真っ黒のまま。
デバッグ出力で文字みてるだけの最近……。
コメント:2件
Re.まるるん
2017-09-22(Fri) 06:55:15
ちょっと主題とはずれるんだけど昔圧縮ファイルを解凍せずに中身みて不要なのをそのまま消せるの作ってなかったでしたっけ?
記憶違いだったらすまんのですが合ってたら使いたいなーと思うのだけど公開はしない予定?
記憶違いだったらすまんのですが合ってたら使いたいなーと思うのだけど公開はしない予定?
Re.織田霧さくら
2017-09-23(Sat) 00:26:52
あれはちょっと公開に向かないツールなので……
その理由のテキスト付でそっちの鯖のappのところに入れておいたのでみてくだはれ。
ほかにもついでに恥豚様とかも追加しといたです。
その理由のテキスト付でそっちの鯖のappのところに入れておいたのでみてくだはれ。
ほかにもついでに恥豚様とかも追加しといたです。
2017-09
11
21:29:49
そんなもんだよな……
「ComicSoon」
漫画発売日リスト取得と登録作家名、作品名で一括検索ツール。
http://www.rengoku.sakura.ne.jp/program/software/comicsoon/index.html
ver 2.1.0 公開。
ローカルにある過去データから一括検索する機能追加~
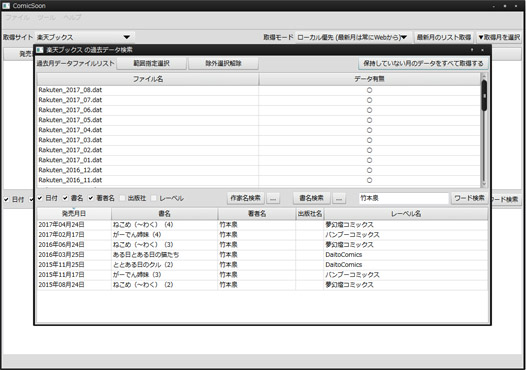
あんまし一括で過去データぶっこぬきしちゃうと、情報サイトのほうでなんか対策とかされそうなのでどうなのかなーとペンディングにしていた機能なんですが。
やっぱ某氏の言うようにように欲しい機能ではあるので、とりあえず試しに追加してみたり。
デバッグビルド中はくっそ重くてどうなんだコレと思ってたのですが、リリースビルドにすると、3年分のデータを数10件の作家名で検索かけても、数秒で終わる……。メチャ軽い。
そんでちょこちょこ試してたらばある事に気づく。
週間連載の作家さんの結果と、月刊連載もしくは不定期連載な作家さんの検索結果が如実に差が出るのまで見えて来ちゃうんだなとかw
情報サイトにもともと三年分しかないので過去三年分しか取れないにしても、月刊ペースの作家さんだと、せいぜい3~4冊ぐらい。
週刊だと普通に10冊ぐらい出てくるんですよね。やっぱ週刊ペースってすげぇ生産ペースだよなと。週間連載が出来る漫画家さんは超人なのだ(コミックマスターJより)
ついでにもう一ネタ
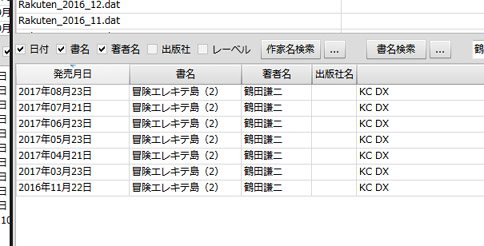
ちょっとまえにも触れたネタだけど。
鶴田謙二氏の冒険エレキテ島2巻、なんか毎月のようにリストに載ってるなーというので、過去データからの検索にかけてみるとこんな感じになってたのねと。
最初は2016年11月22日でそのあとは2017年03月23日からずっと毎月発売日リストにw
ここ最近は担当者が意地になってるのか、プレッシャーかける為に毎月載せてるんじゃないかと邪推w
PGネタとしては、以前から上手く行かない処理があって。
今回のでもつかっているのだけども、長い時間がかかる処理の場合、別スレッドで実行するみたいな処理で、処理中に中断のやり方がよくわからない。
中断するだけならできるんだけど、そのあとスレッドの終了処理タイミングと、実行もとのオブジェクトのデストラクタのタイミングとかでぶち落ちるんですよね。
「中断しますか?」みたいなダイアログだすと、なんでか中断指示だしたスレッドが動き続けて、ダイアログ閉じる前にスレッドの中でやってた処理が終わって処理終了時に実行もとのオブジェクトにシグナルで閉じる指示とか出してるもんだから、これもなんかダイアログ閉じた瞬間に落ちる~。
どうもダイアログもまた別のスレッドで処理してるので、その辺でなんかおかしな事になってるっぽい。
とりあえず中止かの質問ダイアログ出すの止めて進捗のプログレスバーだしてるダイアログのXボタンおしたら、ぶつっと確認無しで終了にしてアレコレやったりしたら、とりあえず落ちないで処理の終了は出来る様になったんですが。
いまいちスマートでない感じに。
この辺あんま情報ない&あっても英語の情報ばかりでこまるぅ。
あとはなんか最近のverのQtのデバッグビルドはなんかおかしい。
異様に遅くなったのもあるけど、今回のツールの場合、Webからファイルをダウンロードするとき、開始するまでにえらく待ち時間があるのと、DL中の現在読み込んだサイズと、全体のサイズてのがシグナルでおくられてくるのだけども、デバッグビルドだとなぜかずっと全体のサイズがつねに-1。
なんかデバッグビルドだとまともに動いてるのかのチェックすらままならなくなってきてるぅ。これほんとどうにかならんのか……。
も一つのほうのゲームPGのほうでは。
とりあえず試しに文字コードutf-8統一路線で進めてみようとおもったのだけども。
utf-8の文字列に対して文字数でsubstr出来るのとかちまちま作り出したところで、やっぱutf-8は文字列操作には向いてないんだなぁと。
ただ、現時点で、wchar_tは使わない、文字コードが環境依存で変わるっていう状況はやはりうざったい。てことで環境に依存しない文字コード固定で…・・っていう方向は間違ってはないとおもうのだけども。どうするのがスマートなのか。
そこでソースコード内のリテラルは全部u8""のutf-8で書く事にして。
で、独自のstring型を用意して、内部ではutf-16(std::wstring)で管理する感じにしてみることに。
独自のstring型はconst char*でもそのまま受け取れる(const char*はutf-8限定)
と、結局QStringのパクリみたいな感じの方向でいくことにw
しかしまあ、const char*で受け取るのも、暗黙でutf-8想定というところが気持ち悪いといえば気持ち悪い。char8_tがないからなぁ。
とはいえ、もしchar8_tあったとしたら何バイトになるのだろうか。
char = u8'a';
てのがわりと最近vc++でも有効になったのだけども。
これって1バイト文字の範囲のutf-8に限るんですよね。
char = u8'あ';
なんてのは当然無効。
んで、ちょうどutf-8対応のsubstr作ってたときに、コードの仕様とかまたみてたのだけど、どうも今まで結構古い仕様を参考にしていたようで、2003年11月からの新しい(つーても2003て随分前じゃん……)仕様だと、どうもutf-8の一文字の最大バイト数は4バイトになるらしい(ニコイチな文字とか特殊なのはべつとして)
以前はasciiコード互換の1バイト文字以外は3~6バイトっていう認識だったのですが。ただこの情報もほんとに最近のなのかよくわからんw
んでもutf-32とutf-8の関係って、utf-32をシリアライズしたものがutf-8という表現で解説してる所もあったりで。utf-32は4バイトじゃないですか。そうなると両者の差があんまり……。
英語圏の1バイト文字しか使わない人達にはutf-8ウマーなんだろうけどさ。
まあ、結局の所、欲しいのはchar8_tではなく、u8""の文字列をconst char*出受け取ると、中身がutf-8なのかどうなのか判らないというところで、これはutf-8デスよと規定するutf-8を扱う型が欲しいと言うだけなのですよね。
現状、utf-16とwchar_tがそんな感じの状況ですよね。
そのままではchar16_tはwchar_tに代入できないですし(内部のバイト列は同じでも別の型なので)。
それのutf-8版が欲しいだけなんですけどね……。
んでもutf-8のまいど文字の先頭位置(バイト単位)で取得するためには毎度先頭から走査するってのは実際組んでみるとうっとうしい仕様だなと。
文字単位で移動するイテレータとかそんなんも作ってみたりとか、一括で文字数とバイト数の対応のリストを作ってからアレコレするみたいな方向とかいろいろ試してみたけど……
普通にutf-16とかに変換しちゃったほうが楽だねコレ。という結論に達したw
utf-8だとstd::regexもダメ臭いし(実際には単なるバイナリ比較になってしまうので、途中の多バイト文字の中のasciiコードにマッチしてしまう)
std::regexで分割する(htmlタグ風のパーサーとか使う時とか)時はサロゲートペアチェックしてのutf-16かutf-32に変換してから……って感じになるのでしょうか。
以前組んだ奴はさろげーとぺあってなんですか? って感じで目線をそらす感じでutf-16のままつかってましたが、特に誤マッチとかもなく普通に使えてたりして。
デバッグビルドの時だけサロゲートペアチェックしてそこで問題無ければリリースビルドではサロゲートペアの処理しないutf-16固定というのも有りなのかなーと言う気も。
ほんと文字コード回りってめんどくさい。
漫画発売日リスト取得と登録作家名、作品名で一括検索ツール。
http://www.rengoku.sakura.ne.jp/program/software/comicsoon/index.html
ver 2.1.0 公開。
ローカルにある過去データから一括検索する機能追加~
あんまし一括で過去データぶっこぬきしちゃうと、情報サイトのほうでなんか対策とかされそうなのでどうなのかなーとペンディングにしていた機能なんですが。
やっぱ某氏の言うようにように欲しい機能ではあるので、とりあえず試しに追加してみたり。
デバッグビルド中はくっそ重くてどうなんだコレと思ってたのですが、リリースビルドにすると、3年分のデータを数10件の作家名で検索かけても、数秒で終わる……。メチャ軽い。
そんでちょこちょこ試してたらばある事に気づく。
週間連載の作家さんの結果と、月刊連載もしくは不定期連載な作家さんの検索結果が如実に差が出るのまで見えて来ちゃうんだなとかw
情報サイトにもともと三年分しかないので過去三年分しか取れないにしても、月刊ペースの作家さんだと、せいぜい3~4冊ぐらい。
週刊だと普通に10冊ぐらい出てくるんですよね。やっぱ週刊ペースってすげぇ生産ペースだよなと。週間連載が出来る漫画家さんは超人なのだ(コミックマスターJより)
ついでにもう一ネタ
ちょっとまえにも触れたネタだけど。
鶴田謙二氏の冒険エレキテ島2巻、なんか毎月のようにリストに載ってるなーというので、過去データからの検索にかけてみるとこんな感じになってたのねと。
最初は2016年11月22日でそのあとは2017年03月23日からずっと毎月発売日リストにw
ここ最近は担当者が意地になってるのか、プレッシャーかける為に毎月載せてるんじゃないかと邪推w
PGネタとしては、以前から上手く行かない処理があって。
今回のでもつかっているのだけども、長い時間がかかる処理の場合、別スレッドで実行するみたいな処理で、処理中に中断のやり方がよくわからない。
中断するだけならできるんだけど、そのあとスレッドの終了処理タイミングと、実行もとのオブジェクトのデストラクタのタイミングとかでぶち落ちるんですよね。
「中断しますか?」みたいなダイアログだすと、なんでか中断指示だしたスレッドが動き続けて、ダイアログ閉じる前にスレッドの中でやってた処理が終わって処理終了時に実行もとのオブジェクトにシグナルで閉じる指示とか出してるもんだから、これもなんかダイアログ閉じた瞬間に落ちる~。
どうもダイアログもまた別のスレッドで処理してるので、その辺でなんかおかしな事になってるっぽい。
とりあえず中止かの質問ダイアログ出すの止めて進捗のプログレスバーだしてるダイアログのXボタンおしたら、ぶつっと確認無しで終了にしてアレコレやったりしたら、とりあえず落ちないで処理の終了は出来る様になったんですが。
いまいちスマートでない感じに。
この辺あんま情報ない&あっても英語の情報ばかりでこまるぅ。
あとはなんか最近のverのQtのデバッグビルドはなんかおかしい。
異様に遅くなったのもあるけど、今回のツールの場合、Webからファイルをダウンロードするとき、開始するまでにえらく待ち時間があるのと、DL中の現在読み込んだサイズと、全体のサイズてのがシグナルでおくられてくるのだけども、デバッグビルドだとなぜかずっと全体のサイズがつねに-1。
なんかデバッグビルドだとまともに動いてるのかのチェックすらままならなくなってきてるぅ。これほんとどうにかならんのか……。
も一つのほうのゲームPGのほうでは。
とりあえず試しに文字コードutf-8統一路線で進めてみようとおもったのだけども。
utf-8の文字列に対して文字数でsubstr出来るのとかちまちま作り出したところで、やっぱutf-8は文字列操作には向いてないんだなぁと。
ただ、現時点で、wchar_tは使わない、文字コードが環境依存で変わるっていう状況はやはりうざったい。てことで環境に依存しない文字コード固定で…・・っていう方向は間違ってはないとおもうのだけども。どうするのがスマートなのか。
そこでソースコード内のリテラルは全部u8""のutf-8で書く事にして。
で、独自のstring型を用意して、内部ではutf-16(std::wstring)で管理する感じにしてみることに。
独自のstring型はconst char*でもそのまま受け取れる(const char*はutf-8限定)
と、結局QStringのパクリみたいな感じの方向でいくことにw
しかしまあ、const char*で受け取るのも、暗黙でutf-8想定というところが気持ち悪いといえば気持ち悪い。char8_tがないからなぁ。
とはいえ、もしchar8_tあったとしたら何バイトになるのだろうか。
char = u8'a';
てのがわりと最近vc++でも有効になったのだけども。
これって1バイト文字の範囲のutf-8に限るんですよね。
char = u8'あ';
なんてのは当然無効。
んで、ちょうどutf-8対応のsubstr作ってたときに、コードの仕様とかまたみてたのだけど、どうも今まで結構古い仕様を参考にしていたようで、2003年11月からの新しい(つーても2003て随分前じゃん……)仕様だと、どうもutf-8の一文字の最大バイト数は4バイトになるらしい(ニコイチな文字とか特殊なのはべつとして)
以前はasciiコード互換の1バイト文字以外は3~6バイトっていう認識だったのですが。ただこの情報もほんとに最近のなのかよくわからんw
んでもutf-32とutf-8の関係って、utf-32をシリアライズしたものがutf-8という表現で解説してる所もあったりで。utf-32は4バイトじゃないですか。そうなると両者の差があんまり……。
英語圏の1バイト文字しか使わない人達にはutf-8ウマーなんだろうけどさ。
まあ、結局の所、欲しいのはchar8_tではなく、u8""の文字列をconst char*出受け取ると、中身がutf-8なのかどうなのか判らないというところで、これはutf-8デスよと規定するutf-8を扱う型が欲しいと言うだけなのですよね。
現状、utf-16とwchar_tがそんな感じの状況ですよね。
そのままではchar16_tはwchar_tに代入できないですし(内部のバイト列は同じでも別の型なので)。
それのutf-8版が欲しいだけなんですけどね……。
んでもutf-8のまいど文字の先頭位置(バイト単位)で取得するためには毎度先頭から走査するってのは実際組んでみるとうっとうしい仕様だなと。
文字単位で移動するイテレータとかそんなんも作ってみたりとか、一括で文字数とバイト数の対応のリストを作ってからアレコレするみたいな方向とかいろいろ試してみたけど……
普通にutf-16とかに変換しちゃったほうが楽だねコレ。という結論に達したw
utf-8だとstd::regexもダメ臭いし(実際には単なるバイナリ比較になってしまうので、途中の多バイト文字の中のasciiコードにマッチしてしまう)
std::regexで分割する(htmlタグ風のパーサーとか使う時とか)時はサロゲートペアチェックしてのutf-16かutf-32に変換してから……って感じになるのでしょうか。
以前組んだ奴はさろげーとぺあってなんですか? って感じで目線をそらす感じでutf-16のままつかってましたが、特に誤マッチとかもなく普通に使えてたりして。
デバッグビルドの時だけサロゲートペアチェックしてそこで問題無ければリリースビルドではサロゲートペアの処理しないutf-16固定というのも有りなのかなーと言う気も。
ほんと文字コード回りってめんどくさい。
2017-09
10
05:28:06
消されるわ
某氏から、コミック発売日検索ツールがDLしたらノートン先生に消されるぞゴルァと。
最近のノートンは誤検出酷いっていうか、もはや検出する努力を放棄してる感じですよね。個人が作ったexeは信頼性0からのスタートなのでとりあえず消しとけって感じで消されるらしいです。
そんでもって、「あんたウィルスとかしこんだろ」とかフリーソフトの開発者が難癖付けられる事態は多発している模様です。
と、自分で開発やってる人にはもはやあたりまえの事態なんですが(開発中のビルドしたばかりのexeを消されるし……)まだまだこの事象は世間一般には浸透してないのかなとかおもたり。
別のアンチウィルスソフトでは、exeのなかのファイルバージョンが設定されていないだけで消される対象になるのだとか。
っていう記事をみつけて、はて、そういえばexeファイルとのプロパティみるとverとかみれたっけな。そういうのなんにも設定してないやと思い至る。
Qtだとどうやるのかなとググってみたらば、.proファイルに書き込めばいいようです。
アプリ情報の埋め込み
ttp://qt-log.open-memo.net/sub/other__embed_app_info.html
vc++の方はどうやるのかといえば、プロジェクトのプロパティのなかのアセンブリ情報ってところから設定できるらしい。
今度からはexe作るときはちゃんと設定しておこう……。
消されると言えばもう一件。
firefox55に上げたらば。アドオンの一覧に「旧式」の文字が出るように。
なんでもfirefox57でこの旧式の文字が出てるアドオンは使用不可になるらしい。
……uBlock orign以外全部「旧式」マークついてるんですけど……_| ̄|○
そんでもって55.0.3にあげた現時点で、Drag & Drop Zonesというアドオンが使用不可に……。
これはページの文字をドラッグで選択して、そのまま文字をドラッグすると画面上にいくつかフィールドがひょうじされてそこにドロップすると、そのフィールドに指定されてる検索エンジンで検索してくれる。
っていうアドオンなんですが。
右クリック不可のサイトとかでも使えたり(なかには無理なところもあるけど)マウスオンリーでさくっと選択、ドラッグの操作だけで検索できるのでわりと常用してたりして。
なので、急に使えなくなると、おもわず同じ動作をやって失敗(どうもドラッグ&ドロップの際に文字列のフォーマット形式が変わったっぽい? で、アドレスが上手く検索エンジンに渡せなくなってしまってる模様)するのをここ数日何度もやってしまうぽ。
しかし、この手の常用してるアドオンが使えなくなるのは一気に不便になるですね。てか、firefoxの最近はいろいろとおかしいので(急にver番号上げ出したあたりから……)まじでアドオン全滅するならそろそろ乗り換えを考えるべきかと……。
この辺のところで多くの人が共通してるのが、「アドオンあってこそのfirefox」なのにそのアドオンを切りすてるとか意味わかんない。
っていうところ。
ほんと、どうにかならんのかねコレ。
まあ、もっとシンプルかつ作りやすいアドオンの開発環境とか揃えてくれるんならいいんですけどね。
ちょっと前にアドオン作ってみるかなと思ったことあったのですが、今のこの旧式扱いされる開発環境と新しい開発環境っぽいのの情報が錯綜してて、これはいま手を出す時期じゃないなって感じだったんですよね。
その辺整理されて1からリセットってのなら、もりもり代替の自分好みのアドオンを作っていくという方向も有りなのかなとかおもたりもするですけど。
もともと、漫画の発売日情報検索ツールも、最初はfirefoxのアドオンとして作ってみようかとおもってた物だったりするし。
ブラウザ上で登録した文字キーワードリストから一括検索してリスト化するみたいなの。
いまのところは静観するより他ない状況か……。
最近のノートンは誤検出酷いっていうか、もはや検出する努力を放棄してる感じですよね。個人が作ったexeは信頼性0からのスタートなのでとりあえず消しとけって感じで消されるらしいです。
そんでもって、「あんたウィルスとかしこんだろ」とかフリーソフトの開発者が難癖付けられる事態は多発している模様です。
と、自分で開発やってる人にはもはやあたりまえの事態なんですが(開発中のビルドしたばかりのexeを消されるし……)まだまだこの事象は世間一般には浸透してないのかなとかおもたり。
別のアンチウィルスソフトでは、exeのなかのファイルバージョンが設定されていないだけで消される対象になるのだとか。
っていう記事をみつけて、はて、そういえばexeファイルとのプロパティみるとverとかみれたっけな。そういうのなんにも設定してないやと思い至る。
Qtだとどうやるのかなとググってみたらば、.proファイルに書き込めばいいようです。
アプリ情報の埋め込み
ttp://qt-log.open-memo.net/sub/other__embed_app_info.html
vc++の方はどうやるのかといえば、プロジェクトのプロパティのなかのアセンブリ情報ってところから設定できるらしい。
今度からはexe作るときはちゃんと設定しておこう……。
消されると言えばもう一件。
firefox55に上げたらば。アドオンの一覧に「旧式」の文字が出るように。
なんでもfirefox57でこの旧式の文字が出てるアドオンは使用不可になるらしい。
……uBlock orign以外全部「旧式」マークついてるんですけど……_| ̄|○
そんでもって55.0.3にあげた現時点で、Drag & Drop Zonesというアドオンが使用不可に……。
これはページの文字をドラッグで選択して、そのまま文字をドラッグすると画面上にいくつかフィールドがひょうじされてそこにドロップすると、そのフィールドに指定されてる検索エンジンで検索してくれる。
っていうアドオンなんですが。
右クリック不可のサイトとかでも使えたり(なかには無理なところもあるけど)マウスオンリーでさくっと選択、ドラッグの操作だけで検索できるのでわりと常用してたりして。
なので、急に使えなくなると、おもわず同じ動作をやって失敗(どうもドラッグ&ドロップの際に文字列のフォーマット形式が変わったっぽい? で、アドレスが上手く検索エンジンに渡せなくなってしまってる模様)するのをここ数日何度もやってしまうぽ。
しかし、この手の常用してるアドオンが使えなくなるのは一気に不便になるですね。てか、firefoxの最近はいろいろとおかしいので(急にver番号上げ出したあたりから……)まじでアドオン全滅するならそろそろ乗り換えを考えるべきかと……。
この辺のところで多くの人が共通してるのが、「アドオンあってこそのfirefox」なのにそのアドオンを切りすてるとか意味わかんない。
っていうところ。
ほんと、どうにかならんのかねコレ。
まあ、もっとシンプルかつ作りやすいアドオンの開発環境とか揃えてくれるんならいいんですけどね。
ちょっと前にアドオン作ってみるかなと思ったことあったのですが、今のこの旧式扱いされる開発環境と新しい開発環境っぽいのの情報が錯綜してて、これはいま手を出す時期じゃないなって感じだったんですよね。
その辺整理されて1からリセットってのなら、もりもり代替の自分好みのアドオンを作っていくという方向も有りなのかなとかおもたりもするですけど。
もともと、漫画の発売日情報検索ツールも、最初はfirefoxのアドオンとして作ってみようかとおもってた物だったりするし。
ブラウザ上で登録した文字キーワードリストから一括検索してリスト化するみたいなの。
いまのところは静観するより他ない状況か……。
2017-09
05
03:26:19
でもまた暑くなったりするんだろうな
ここ数日、急に秋っぽい涼しい日が続いてますが、一時的な物でまたしばらくしたら残暑キターな感じになるんでしょうかね。
そんななか。
そろそろほんとゲーム作ろうよってかんじで久々にvc++立ち上げたのですが。
VisualStudio2017 update3来てたのですね。c++17対応がちょっと増えてる。
コンパイラの実装状況
ttps://cpprefjp.github.io/implementation-status.html
「if文とswitch文の条件式と初期化を分離」
これは早くほしいなーとおもってた物の一つですね。
if(int index=getIndex(); index == 0){
//...
}
で、スコープの外ではindexはもう消えてるっていう。
おなじことをやろうと思うと以前は
{
int index=getIndex();
if( index == 0){
//...
}
}
と無駄にスコープで無駄に囲わなきゃいけなかったので。
このためだけにインデント深くなるのはうっとうしい。
あと自分ルールで大体決まってる返値の受け取り変数に同名が使いやすくなるというのも。
if(auto result=getHoge(); result != nullptr){
//...
}
if(auto result=getHoge2(); result != nullptr){
//...
}
なんて続けて書いてもお互いのresultは別ものでそれぞれのスコープの終わりで消滅するので衝突も起らないのです。
「if constexpr」
最初この文字を見たときには、キタコレとおもったのですが、中身みてしょんぼりの奴w
欲しかったのはコンパイル時なのか実行時なのかで処理を切り替えるようなものだったのですが、if constexprはテンプレートの実体化を抑制する機能、ということらしい。
なので今のところ使うあてはなさそう。
コンパイル時なのか実行時なのかで処理を切り替える機能欲しいな-。
たとえばべき上を求める場合、コンパイル時はconstexpr関数で適当に書いたので実行して(どうせコンパイル時間中に計算されるので実装は適当でも答えあってれば実行時にはなんの影響もない)実行時にはstd::pow使う。みたいなのができたらなと。一つの関数で実行時とコンパイル時で切り替えられるのが欲しいぽ。
現行ではそれらは別けて別関数とかにしないと無理ぽなので。
「構造化束縛」
タプルが使いやすくなるですね。正直std::get<n>(taple)て書き方は助長過ぎてダサ過ぎ感はんぱないので。
「ラムダ式をconstexprとして使用できるようにする」
ちょこっと一回だけとか使う物をconstexpr関数を定義しなくてもラムダ式で書いちゃえるのは楽でよいですね。
残念なのはまだ未対応の
「畳み込み式」
単に可変長引数の中身を連結するだけのときでもまだ再帰で書かなきゃ行けないのかー。めんどくさー。
もっとがっかりなのは、Qtで今回ふえたのつかえねーじゃんってこと。
「if文とswitch文の条件式と初期化を分離」試してみたら普通にエラー。
てかやっぱQt5.9からなぜかmsvc2017の32bitビルド版が提供されなくなってるんですよね。QTのブログでもつっこまれてたけど、これ以上数増やしたくないだの時代はもう64bitだよ何か問題でも? とかなめた解答返ってきてたりするし。msvc2017は2015とコンパチだからmsvc2015版でもc++17対応増えたのは適用されてたりするのかなと期待したのですがやっぱ無理ぽらしい。
c++17対応おくれてんじゃねーか。影響でまくりだよ……
なにげに未だにshared_ptrでmake_shared使うと引数無しの場合赤線でるし。
clang解析ONにしたらいいんだろうけど、以前のverでソースコードロックして上書き保存不可&大量のゴミバックアップファイルを大量生産するバグなのか環境依存なのかの現象があって以来clang解析offがデフォだし。
むー。
なんかいろいろ不満たらたら。
だのになぜかまたQtプログラミング。
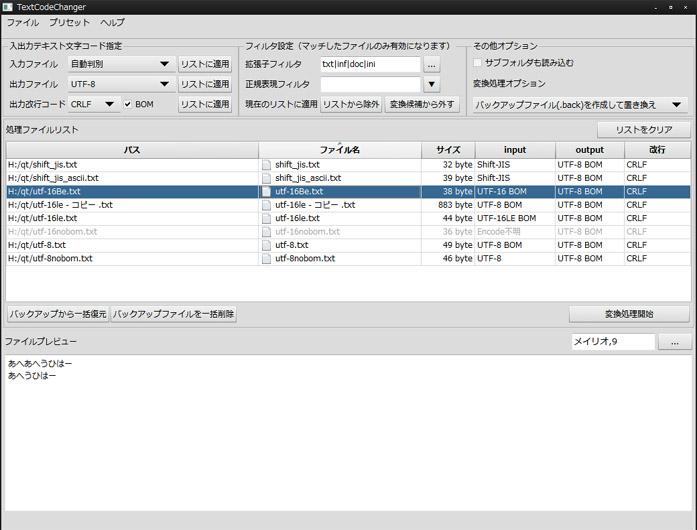
vc++のプロジェクトもソースコードはutf8に統一しようかなとおもたのですが、文字コード一括変換するツールいくつか物色してみたところ、どれも変換自体はうまくいくのですが、
・フォルダドロップでサブフォルダまで登録
・フィルタで指定した拡張子のファイルのみを読み込む
・文字コード自動判別で成功してるのか変換前に確認
・変換後バックアップからの復元
このあたりが全部そろってるのが見つからない。こっちはあるけどあっちがないみたいな感じでなかなか良い物がないぽ。
特に三つ目が無いんですよね。
自動判別に自信があるのかしらないけど、もともと100%解析出来る類のものではないですし。一旦ほんとにあってるのか確認ぐらいはしたいですよね。
バックアップの方法もいくつか選択出来るといいですよね。
で、結局自分でつくることに。
今のところ、バックアップ回りは拡張子変えたバックアップファイルを同じ場所につくる(復元機能で一括復元可)元ファイルをゴミ箱に送る(ゴミ箱から元の場所にで復元可能)バックアップ取らずに上書き(変換うまくいくの確認済みの場合)
の三つを用意。
バックアップファイルの一括削除もあるといいかな。
サブフォルダまで登録できるとバックアップファイルを消すのは結構大変なので。
変換前に自動判別結果の文字コードでテキストを実際に読み込んでプレビュー機能あたりがやっぱ結構ほしい機能なんじゃないかなと。
で、うまく判定できてなかったら手動で個別に読み込みコードを指定し直して~とできるのはやはり便利。
……自動判定あたり結構適当に組んだので、余所様のところの自動判定の精度に自信ありって所にはまるで対抗出来る自信ないので、そのへんのフォローも兼ねてる……w
実際上のプリスク画像のでも、bom無しutf-16の判定失敗してますしね。
まあ中身の文章量とか内容(使われている文字コード種類)でも判定精度に影響あるのでアレですが。
ちないま上の貼り付け画像みてて気づいたけど「utf-16le - コピー .txt」がutf-8判定になってるのは、変換テストでutf-8に変換後のファイルだからですとフォロー。
なにげにちょっと前に作ったソースコード閲覧用のツールの文字コード判別ルーチン使い回してるのですが、世にある文字コード変換ツールも大抵、開発者の人、他にエディタも作ってたりして。その文字コード判定部を使い回してるパターンおおいんだなとおもって、同じ流れで作ってるのに気づいて然もありなん……となんだか納得しちゃったり。
ちょいと嵌ったのが、QTは改行コードの\r\nと\nの判別は自動でやってくれて、書き出しもテキストモードで書き出すと、環境に合わせた改行コードでかってに出力してくれる便利機能付なんですが……。
今回のように改行コードを自分で指定したいってときにどうやるのかちょっと迷った。
結論は単に自前で改行コード付け足しつつ、テキストモードじゃなくてバイナリで書くだけという、ちょっと考えりゃ判るじゃんというオチでしたがw
なんでも自動化されてると普通に使う分には便利でいいんですが、ちょっとつっこんだことをやろうとおもうと、かえって面倒だったり。
で、vc++でゲームプログラミングーのつもりがまずソースコードの文字コード全部変換しよう→変換ツールなんだかんだで結局自作といきなり脱線ぽw
しかし、ここしばらくvc++触ってなかったけど……。
文字コード回りはやっぱまだまだコレって言う決定的な判断基準がないなと。
vc++とDXライブラリでゲーム開発という前提で。
まず考慮すべきは、最終的な出力にはwinの内部文字コードのutf-16が使われるということ。
んでvc++は、ソースファイルの文字コードがなんであろうと""で囲われた文字リテラルの文字コードはshift-jis(正確には違うけどまあ同じ)になる。
で近年、c++11の機能で、
u"" = utf-16
U"" = utf-32
u8"" = utf-8
と、プレフィックスを付けることで文字リテラルの文字コードをプログラマが明示的に指定出来る様になった。
んでもって厄介なのはvc++の文字コードセット設定の
「マルチバイト文字」
「Unicode」
という設定。
混乱の元ですね。
これらの両設定で同じソースコードを扱えるようにするためにTCHARという文字用の型があり、「マルチバイト文字」ではchar、「Unicode」ではwchar_tになる。
で、wchar_tはプラットフォーム依存で中身がかわる。winなら2バイト、unixだと4バイトとかいった風に。
文字リテラルは_T("")というマクロで中身が文字コード設定によってconst char*とconst wchar_t*に振り分けられます。
んでもってutf-8は1バイト単位で扱うcharなので「Unicode」を選択してしまうとTCHARは使えなくなります。2バイト単位とか意味無いですし。
となるとutf-8はunicodeだけど、「マルチバイト文字」を選択するべき?
なんていう混乱も引き起こしたりと、TCHAR回り、vc++の文字コード設定回りは、はっきり言ってぐだぐだです。時代遅れまったなし。
んで、どうするのがベターなのかしばらく考えて見たところ、自分なりの結論は……。
「TCAHRとか_T("")マクロあたりを窓から投げ捨てること」
ですw
そもそもこの辺はwindows上で書くwin依存のコードで、TCHARだとか_T("")とか使ったソースコードを余所の環境にもっていったとき(たとえばQTとか)全部書き直さなければならなくなる。
winで組む場合、最終的な出力でutf-16に変換すれば、後は内部文字文字コードは何でも良いわけです。
そうなると、ソースコードはutf-8で統一。文字リテラルもu8""でutf-8で統一。
DXライブラリの場合なら
std::string str = u8"あいうえお";
DrawString( 0, 0, toUtf16(str), -1);
な感じで、出力の際にutf-16に変換して使うのが一番いいんじゃないかなーと。
vc++の文字コードセットは「Unicode」で。
DXライブラリにも文字コードの変換機能はあるのですが、なぜか文字コードセットが「Unicode」だと使えないので、(wchar_t=2バイト単位で文字を受け取ってしまうので、そこから1バイトずつ拾って変換てのがネックなんだろうな……)自前で変換、もとい上の例では変換したのをDrawStringに送ってますが、実際にはDrawStringのラッパを作ってutf-8文字列を直接受け取って内部で変換して表示すると言う形になるでしょうか。
……char8_tがなく、charで受け取るしかないので、utf-8の文字列を限定で受け取る……というのが出来ず、ローカルルールで文字列はすべてutf-8限定とする。というようなかんじにせざるを得ず、スマートに書けないのがアレですが。
utf-8の泣き所は[]での添え字アクセスでの文字数単位での出来ない所なのですが(substrとかも)その辺の機能追加したu8stringとか自分で作るのがいいのかな?
最終的にはutf-16になるので文字コードセット「マルチバイト文字」はもはや化石設定。使うべきではないし、つかたっところで将来的にもなんのメリットもないぽ。
そんな感じで運用すれば、DXライブラリの機能とかの環境依存機能部分をのぞいた所は、Qtとか他の環境のソースコードの互換もある程度は取れるかなと。
んで結局、まずはwin依存コードを排除すなわち
「TCAHRとか_T("")マクロあたりを窓から投げ捨てること」
という結論に。
内部コードにutf-8はほんとにこれがベストなのかはまだまだ不透明ですけど……。
少なくとも、utf-16はstd::regexから見捨てられたようですし(サロゲートペアあたりの処理とかの問題ぽ)現行windowsの内部コードがutf-16であるということ以外では使いどころの薄い文字コードとなりつつあるぽ。
utf-32にしても、固定長バイトの文字コード幻想は打ち破られて、結局いまの所ではutf-8がベターというところでしょうか。
utf-8でもbom付bom無しとかの問題もありますしね。
ほんと文字コード回りは混迷をきわめるぅ。
c++の標準機能での文字コード変換機能だったcodecvtはc++17ではdeprecated
になったそうですし。理由はセキュアな問題だそうです。代替用意してから消えてよと……_| ̄|○
winならwin32apiで環境依存だけどMultiByteToWideCharを使うし、QtならQtの機能で文字変換ついてるのでまあ、困りはしないんだけど……
でももともとcodecvtてパフォーマンス的にも微妙とかなんかでみた記憶もあるしな。
ちなみにQtのQStringは内部コードはutf-16なんですよね。
でも基本的には
utf-8→QString→環境にあわせた文字コード
と言った感じでその中継ぎをQStringがやってくれるので、実際の所QStringの内部文字コードが何であるかは意識しなくてもよい感じになってるのです。
内部がutf-16なのはやはり文字単位でのアクセスがやりやすいから何でしょうね。
そもQTはGUIアプリとか向けなので、事情がちがう部分もあるのですよね。
GUIアプリなら、文字列を右から左に送るたびに文字コード変換してもべつにいいけどゲームPGでは1フレーム内に必要な処理を行なわなければならないと、速度的な制限があるため、文字コード変換というコストもなるべく抑えたいというところもあって。
そうなると、最初からutf-16で統一、u""で統一。というのも案としては出てくるのですが、一文字ずつ出力とかするさいにサロゲートペアの処理はどーするの? とか、素直に使えなかったりする部分もあるので(とはいえ普通の日本語しか使ってなければサロゲートペア無視しても問題にひっかかる確率低いですけどね)
あとwchar_tとutf-16はwin環境においては、同じ文字の中身のバイト列は同一だけども、型が違うのでそのまま代入出来ませんしね。
reinterpret_castとか使うのおっかねぇ。gotoよりおっかねぇ(私だけ?)
そんな感じでとりあえずutf-8統一案が今のところは現実的ぽ?
そんななか。
そろそろほんとゲーム作ろうよってかんじで久々にvc++立ち上げたのですが。
VisualStudio2017 update3来てたのですね。c++17対応がちょっと増えてる。
コンパイラの実装状況
ttps://cpprefjp.github.io/implementation-status.html
「if文とswitch文の条件式と初期化を分離」
これは早くほしいなーとおもってた物の一つですね。
if(int index=getIndex(); index == 0){
//...
}
で、スコープの外ではindexはもう消えてるっていう。
おなじことをやろうと思うと以前は
{
int index=getIndex();
if( index == 0){
//...
}
}
と無駄にスコープで無駄に囲わなきゃいけなかったので。
このためだけにインデント深くなるのはうっとうしい。
あと自分ルールで大体決まってる返値の受け取り変数に同名が使いやすくなるというのも。
if(auto result=getHoge(); result != nullptr){
//...
}
if(auto result=getHoge2(); result != nullptr){
//...
}
なんて続けて書いてもお互いのresultは別ものでそれぞれのスコープの終わりで消滅するので衝突も起らないのです。
「if constexpr」
最初この文字を見たときには、キタコレとおもったのですが、中身みてしょんぼりの奴w
欲しかったのはコンパイル時なのか実行時なのかで処理を切り替えるようなものだったのですが、if constexprはテンプレートの実体化を抑制する機能、ということらしい。
なので今のところ使うあてはなさそう。
コンパイル時なのか実行時なのかで処理を切り替える機能欲しいな-。
たとえばべき上を求める場合、コンパイル時はconstexpr関数で適当に書いたので実行して(どうせコンパイル時間中に計算されるので実装は適当でも答えあってれば実行時にはなんの影響もない)実行時にはstd::pow使う。みたいなのができたらなと。一つの関数で実行時とコンパイル時で切り替えられるのが欲しいぽ。
現行ではそれらは別けて別関数とかにしないと無理ぽなので。
「構造化束縛」
タプルが使いやすくなるですね。正直std::get<n>(taple)て書き方は助長過ぎてダサ過ぎ感はんぱないので。
「ラムダ式をconstexprとして使用できるようにする」
ちょこっと一回だけとか使う物をconstexpr関数を定義しなくてもラムダ式で書いちゃえるのは楽でよいですね。
残念なのはまだ未対応の
「畳み込み式」
単に可変長引数の中身を連結するだけのときでもまだ再帰で書かなきゃ行けないのかー。めんどくさー。
もっとがっかりなのは、Qtで今回ふえたのつかえねーじゃんってこと。
「if文とswitch文の条件式と初期化を分離」試してみたら普通にエラー。
てかやっぱQt5.9からなぜかmsvc2017の32bitビルド版が提供されなくなってるんですよね。QTのブログでもつっこまれてたけど、これ以上数増やしたくないだの時代はもう64bitだよ何か問題でも? とかなめた解答返ってきてたりするし。msvc2017は2015とコンパチだからmsvc2015版でもc++17対応増えたのは適用されてたりするのかなと期待したのですがやっぱ無理ぽらしい。
c++17対応おくれてんじゃねーか。影響でまくりだよ……
なにげに未だにshared_ptrでmake_shared使うと引数無しの場合赤線でるし。
clang解析ONにしたらいいんだろうけど、以前のverでソースコードロックして上書き保存不可&大量のゴミバックアップファイルを大量生産するバグなのか環境依存なのかの現象があって以来clang解析offがデフォだし。
むー。
なんかいろいろ不満たらたら。
だのになぜかまたQtプログラミング。
vc++のプロジェクトもソースコードはutf8に統一しようかなとおもたのですが、文字コード一括変換するツールいくつか物色してみたところ、どれも変換自体はうまくいくのですが、
・フォルダドロップでサブフォルダまで登録
・フィルタで指定した拡張子のファイルのみを読み込む
・文字コード自動判別で成功してるのか変換前に確認
・変換後バックアップからの復元
このあたりが全部そろってるのが見つからない。こっちはあるけどあっちがないみたいな感じでなかなか良い物がないぽ。
特に三つ目が無いんですよね。
自動判別に自信があるのかしらないけど、もともと100%解析出来る類のものではないですし。一旦ほんとにあってるのか確認ぐらいはしたいですよね。
バックアップの方法もいくつか選択出来るといいですよね。
で、結局自分でつくることに。
今のところ、バックアップ回りは拡張子変えたバックアップファイルを同じ場所につくる(復元機能で一括復元可)元ファイルをゴミ箱に送る(ゴミ箱から元の場所にで復元可能)バックアップ取らずに上書き(変換うまくいくの確認済みの場合)
の三つを用意。
バックアップファイルの一括削除もあるといいかな。
サブフォルダまで登録できるとバックアップファイルを消すのは結構大変なので。
変換前に自動判別結果の文字コードでテキストを実際に読み込んでプレビュー機能あたりがやっぱ結構ほしい機能なんじゃないかなと。
で、うまく判定できてなかったら手動で個別に読み込みコードを指定し直して~とできるのはやはり便利。
……自動判定あたり結構適当に組んだので、余所様のところの自動判定の精度に自信ありって所にはまるで対抗出来る自信ないので、そのへんのフォローも兼ねてる……w
実際上のプリスク画像のでも、bom無しutf-16の判定失敗してますしね。
まあ中身の文章量とか内容(使われている文字コード種類)でも判定精度に影響あるのでアレですが。
ちないま上の貼り付け画像みてて気づいたけど「utf-16le - コピー .txt」がutf-8判定になってるのは、変換テストでutf-8に変換後のファイルだからですとフォロー。
なにげにちょっと前に作ったソースコード閲覧用のツールの文字コード判別ルーチン使い回してるのですが、世にある文字コード変換ツールも大抵、開発者の人、他にエディタも作ってたりして。その文字コード判定部を使い回してるパターンおおいんだなとおもって、同じ流れで作ってるのに気づいて然もありなん……となんだか納得しちゃったり。
ちょいと嵌ったのが、QTは改行コードの\r\nと\nの判別は自動でやってくれて、書き出しもテキストモードで書き出すと、環境に合わせた改行コードでかってに出力してくれる便利機能付なんですが……。
今回のように改行コードを自分で指定したいってときにどうやるのかちょっと迷った。
結論は単に自前で改行コード付け足しつつ、テキストモードじゃなくてバイナリで書くだけという、ちょっと考えりゃ判るじゃんというオチでしたがw
なんでも自動化されてると普通に使う分には便利でいいんですが、ちょっとつっこんだことをやろうとおもうと、かえって面倒だったり。
で、vc++でゲームプログラミングーのつもりがまずソースコードの文字コード全部変換しよう→変換ツールなんだかんだで結局自作といきなり脱線ぽw
しかし、ここしばらくvc++触ってなかったけど……。
文字コード回りはやっぱまだまだコレって言う決定的な判断基準がないなと。
vc++とDXライブラリでゲーム開発という前提で。
まず考慮すべきは、最終的な出力にはwinの内部文字コードのutf-16が使われるということ。
んでvc++は、ソースファイルの文字コードがなんであろうと""で囲われた文字リテラルの文字コードはshift-jis(正確には違うけどまあ同じ)になる。
で近年、c++11の機能で、
u"" = utf-16
U"" = utf-32
u8"" = utf-8
と、プレフィックスを付けることで文字リテラルの文字コードをプログラマが明示的に指定出来る様になった。
んでもって厄介なのはvc++の文字コードセット設定の
「マルチバイト文字」
「Unicode」
という設定。
混乱の元ですね。
これらの両設定で同じソースコードを扱えるようにするためにTCHARという文字用の型があり、「マルチバイト文字」ではchar、「Unicode」ではwchar_tになる。
で、wchar_tはプラットフォーム依存で中身がかわる。winなら2バイト、unixだと4バイトとかいった風に。
文字リテラルは_T("")というマクロで中身が文字コード設定によってconst char*とconst wchar_t*に振り分けられます。
んでもってutf-8は1バイト単位で扱うcharなので「Unicode」を選択してしまうとTCHARは使えなくなります。2バイト単位とか意味無いですし。
となるとutf-8はunicodeだけど、「マルチバイト文字」を選択するべき?
なんていう混乱も引き起こしたりと、TCHAR回り、vc++の文字コード設定回りは、はっきり言ってぐだぐだです。時代遅れまったなし。
んで、どうするのがベターなのかしばらく考えて見たところ、自分なりの結論は……。
「TCAHRとか_T("")マクロあたりを窓から投げ捨てること」
ですw
そもそもこの辺はwindows上で書くwin依存のコードで、TCHARだとか_T("")とか使ったソースコードを余所の環境にもっていったとき(たとえばQTとか)全部書き直さなければならなくなる。
winで組む場合、最終的な出力でutf-16に変換すれば、後は内部文字文字コードは何でも良いわけです。
そうなると、ソースコードはutf-8で統一。文字リテラルもu8""でutf-8で統一。
DXライブラリの場合なら
std::string str = u8"あいうえお";
DrawString( 0, 0, toUtf16(str), -1);
な感じで、出力の際にutf-16に変換して使うのが一番いいんじゃないかなーと。
vc++の文字コードセットは「Unicode」で。
DXライブラリにも文字コードの変換機能はあるのですが、なぜか文字コードセットが「Unicode」だと使えないので、(wchar_t=2バイト単位で文字を受け取ってしまうので、そこから1バイトずつ拾って変換てのがネックなんだろうな……)自前で変換、もとい上の例では変換したのをDrawStringに送ってますが、実際にはDrawStringのラッパを作ってutf-8文字列を直接受け取って内部で変換して表示すると言う形になるでしょうか。
……char8_tがなく、charで受け取るしかないので、utf-8の文字列を限定で受け取る……というのが出来ず、ローカルルールで文字列はすべてutf-8限定とする。というようなかんじにせざるを得ず、スマートに書けないのがアレですが。
utf-8の泣き所は[]での添え字アクセスでの文字数単位での出来ない所なのですが(substrとかも)その辺の機能追加したu8stringとか自分で作るのがいいのかな?
最終的にはutf-16になるので文字コードセット「マルチバイト文字」はもはや化石設定。使うべきではないし、つかたっところで将来的にもなんのメリットもないぽ。
そんな感じで運用すれば、DXライブラリの機能とかの環境依存機能部分をのぞいた所は、Qtとか他の環境のソースコードの互換もある程度は取れるかなと。
んで結局、まずはwin依存コードを排除すなわち
「TCAHRとか_T("")マクロあたりを窓から投げ捨てること」
という結論に。
内部コードにutf-8はほんとにこれがベストなのかはまだまだ不透明ですけど……。
少なくとも、utf-16はstd::regexから見捨てられたようですし(サロゲートペアあたりの処理とかの問題ぽ)現行windowsの内部コードがutf-16であるということ以外では使いどころの薄い文字コードとなりつつあるぽ。
utf-32にしても、固定長バイトの文字コード幻想は打ち破られて、結局いまの所ではutf-8がベターというところでしょうか。
utf-8でもbom付bom無しとかの問題もありますしね。
ほんと文字コード回りは混迷をきわめるぅ。
c++の標準機能での文字コード変換機能だったcodecvtはc++17ではdeprecated
になったそうですし。理由はセキュアな問題だそうです。代替用意してから消えてよと……_| ̄|○
winならwin32apiで環境依存だけどMultiByteToWideCharを使うし、QtならQtの機能で文字変換ついてるのでまあ、困りはしないんだけど……
でももともとcodecvtてパフォーマンス的にも微妙とかなんかでみた記憶もあるしな。
ちなみにQtのQStringは内部コードはutf-16なんですよね。
でも基本的には
utf-8→QString→環境にあわせた文字コード
と言った感じでその中継ぎをQStringがやってくれるので、実際の所QStringの内部文字コードが何であるかは意識しなくてもよい感じになってるのです。
内部がutf-16なのはやはり文字単位でのアクセスがやりやすいから何でしょうね。
そもQTはGUIアプリとか向けなので、事情がちがう部分もあるのですよね。
GUIアプリなら、文字列を右から左に送るたびに文字コード変換してもべつにいいけどゲームPGでは1フレーム内に必要な処理を行なわなければならないと、速度的な制限があるため、文字コード変換というコストもなるべく抑えたいというところもあって。
そうなると、最初からutf-16で統一、u""で統一。というのも案としては出てくるのですが、一文字ずつ出力とかするさいにサロゲートペアの処理はどーするの? とか、素直に使えなかったりする部分もあるので(とはいえ普通の日本語しか使ってなければサロゲートペア無視しても問題にひっかかる確率低いですけどね)
あとwchar_tとutf-16はwin環境においては、同じ文字の中身のバイト列は同一だけども、型が違うのでそのまま代入出来ませんしね。
reinterpret_castとか使うのおっかねぇ。gotoよりおっかねぇ(私だけ?)
そんな感じでとりあえずutf-8統一案が今のところは現実的ぽ?
Sun
Mon
Tue
Wed
Thu
Fri
Sat
01
02
03
04
05
■
■
でもまた暑くなったりするんだろうな
06
07
08
09
10
■
■
消されるわ
11
■
■
そんなもんだよな……
12
13
14
15
16
17
18
■
■
ある意味キモイ
[敬老の日]
[敬老の日]
19
20
21
22
23
[秋分の日]
24
25
26
27
■
■
もはや何処も信用が……
28
29
30
total:2206644 t:373 y:485
■記事タイトル■
■年度別リスト■
2026年
2026年12月(0)2026年11月(0)
2026年10月(0)
2026年09月(0)
2026年08月(0)
2026年07月(0)
2026年06月(0)
2026年05月(0)
2026年04月(0)
2026年03月(1)
2026年02月(3)
2026年01月(3)
2025年
2025年12月(1)2025年11月(1)
2025年10月(2)
2025年09月(5)
2025年08月(3)
2025年07月(1)
2025年06月(2)
2025年05月(1)
2025年04月(2)
2025年03月(3)
2025年02月(8)
2025年01月(3)
2024年
2024年12月(1)2024年11月(2)
2024年10月(1)
2024年09月(2)
2024年08月(1)
2024年07月(1)
2024年06月(5)
2024年05月(2)
2024年04月(1)
2024年03月(6)
2024年02月(4)
2024年01月(3)
2023年
2023年12月(3)2023年11月(1)
2023年10月(2)
2023年09月(3)
2023年08月(3)
2023年07月(3)
2023年06月(7)
2023年05月(8)
2023年04月(2)
2023年03月(1)
2023年02月(2)
2023年01月(3)
2022年
2022年12月(4)2022年11月(3)
2022年10月(1)
2022年09月(3)
2022年08月(3)
2022年07月(2)
2022年06月(1)
2022年05月(3)
2022年04月(2)
2022年03月(2)
2022年02月(1)
2022年01月(6)
2021年
2021年12月(8)2021年11月(3)
2021年10月(4)
2021年09月(6)
2021年08月(2)
2021年07月(1)
2021年06月(3)
2021年05月(2)
2021年04月(2)
2021年03月(3)
2021年02月(1)
2021年01月(4)
2020年
2020年12月(3)2020年11月(7)
2020年10月(2)
2020年09月(3)
2020年08月(1)
2020年07月(3)
2020年06月(7)
2020年05月(5)
2020年04月(8)
2020年03月(4)
2020年02月(2)
2020年01月(4)
2019年
2019年12月(1)2019年11月(1)
2019年10月(2)
2019年09月(1)
2019年08月(3)
2019年07月(2)
2019年06月(2)
2019年05月(2)
2019年04月(4)
2019年03月(1)
2019年02月(7)
2019年01月(1)
2018年
2018年12月(1)2018年11月(1)
2018年10月(5)
2018年09月(1)
2018年08月(5)
2018年07月(1)
2018年06月(1)
2018年05月(1)
2018年04月(2)
2018年03月(2)
2018年02月(1)
2018年01月(1)
2017年
2017年12月(2)2017年11月(1)
2017年10月(2)
2017年09月(5)
2017年08月(8)
2017年07月(2)
2017年06月(1)
2017年05月(1)
2017年04月(3)
2017年03月(5)
2017年02月(7)
2017年01月(8)
2016年
2016年12月(7)2016年11月(2)
2016年10月(3)
2016年09月(7)
2016年08月(8)
2016年07月(10)
2016年06月(17)
2016年05月(6)
2016年04月(8)
2016年03月(10)
2016年02月(5)
2016年01月(10)
2015年
2015年12月(7)2015年11月(7)
2015年10月(13)
2015年09月(7)
2015年08月(7)
2015年07月(5)
2015年06月(4)
2015年05月(5)
2015年04月(2)
2015年03月(4)
2015年02月(1)
2015年01月(7)
2014年
2014年12月(12)2014年11月(8)
2014年10月(4)
2014年09月(6)
2014年08月(7)
2014年07月(4)
2014年06月(2)
2014年05月(5)
2014年04月(4)
2014年03月(8)
2014年02月(4)
2014年01月(8)
2013年
2013年12月(15)2013年11月(8)
2013年10月(3)
2013年09月(3)
2013年08月(8)
2013年07月(0)
2013年06月(0)
2013年05月(0)
2013年04月(0)
2013年03月(0)
2013年02月(0)
2013年01月(0)
■レス履歴■
■ファイル抽出■
■ワード検索■
堕天使の煉獄
https://rengoku.sakura.ne.jp
管理人
織田霧さくら(oda-x)
E-mail (■を@に)
oda-x■rengoku.sakura.ne.jp