堕天使の煉獄
2016-08
29
07:05:55
まだまだ知らないことばかり
一段落ついて、一眠り~としてたら、横になってふーと一息つくと、やっぱ出てきちゃうんですよね。あそこはこうしてれば、とか、あそこはこうすべきだ~とか。
そんな感じで、結局1から組み直しとかすることに(ぉ
まず、もう統合アーカイバ系のDLLは最初から使わない方向で。書庫ファイルかどうかのチェックも、アーカイバ内ドキュメントみるに、チェックの強度で、「標準」てのが、ヘッダのチェック。これは多分。localヘッダとcentralヘッダの重複部分のチェックだとおもわれ。これは普通に自前の読み込みルーチンの中でやってる。チェックの一番キツイ奴でも、ヘッダ内のcrc32の項目の値と、圧縮ファイルのcrc32の値を再チェックするという項目が増えるぐらいのもののようで。それは現状自前のではやってないんですけど(ファイルデータからcrc32の値取得するのってどのくらいコスト掛かるのかもよくわかってないってのもあって)とにかく、その辺ももう、自前でやってるんだなとおもうと、もう完全にアーカイバDLLいらんやん。ってことに。
んで、それをパージすることで何が得かというと、windows.hをインクルードしなくて済む用になるということ。
windows.hインクルードすると、大量のdefineマクロが追加されて、名前空間をレイプしやがるので、出来ればしたくないものであります。
vcだとそこまで気にならないのですが、Qt creatorだと、ファックされた名前空間からどばどばと使うあてもない候補が並んで、欲しいものを探すのに苦労する(そうならないように細かく名前空間とか別けてるのに…)のがなんともファッキンです。
で、それでアーカイバDLLつかわなければwindows.hも使わなくていいなーとおもったのですが。もう一個windows.hが必要なもの内部で使ってたのを思い出す。
……ゴミ箱。
ファイルを削除するときに、ゴミ箱にいれるっていうのは、windowsのshellの機能とかなんとかで、windows.hとともにShellAPI.hのインクルードが必要で、そんでまたなんとも使いにくい仕様のSHFileOperationとかいうAPIを使わないと、ゴミ箱にファイルを捨てる事が出来ないという。
で、アーカイバDLLパージしたのに、ゴミ箱の所為で結局windows.h外せないのかよ。とかおもったのですが、そこで、そうかこれ、コマンドラインでファイルパス渡して、渡された物をゴミ箱に放り込むという別アプリにしてしまえばいいのかと。
……windows.h使いたくないだけのために、exeにファイルをドラッグするとファイルがゴミ箱に捨てられるだけのアプリを組むとか、なんだかなぁ……な感じですが。でも今後もQTつかうんならまあ便利かなと言う気も。
で、いざ作ろうと思ったところで。
うまく動かない~。
exeファイル単体にエクスプローラ上でファイルをドロップするときはちゃんと動くんだけど、QT上でQProcessから実行すると、「QProcess: destroyed while process still running」とかでたうえで、ゴミ箱にファイルはいらなーい。
なんかプロセスが終了出来てないのに終了しようとしたよ? ってきなメッセージだとおもうのですが。
コンソールアプリの最後はgetcharでキー入力待ちしてるのだけど、それはcloseWriteChannelというもので回避出来るはずなので、自動でプロセスは終わってるはずなんだけどなぁ……。
QProcessでは別プロセスを開始するのに、startとexecuteそれにstartDetachedと
いうのがあって、startは子プロセスとして。startDetachedは独立したプロセスとして起動するんだとか。executeはstartとなんか違うらしいのですが、サンプルが見つからなかったのでよくわからず。
とりあえずstartDetachedに変えてみたら、コンソールが表示され、ゴミ箱にファイルを送れるようにはなる。
が、なんかおかしい。
動作的には、書庫ファイルの中身編集した結果を、メモリバッファ上にファイルイメージを構築。それが終わったら、元ファイルをゴミ箱にすて、元ファイル名と同じ名前をつけてメモリバッファ上のものをファイルとして保存。
てな感じの上書きプロセスなんだけど、実行してみると、ファイルがゴミ箱に行くだけで、元ファイル名のファイルは保存されてない。
……というか、「上書き保存」の後に「ゴミ箱に捨てる」が実行されてるっぽいw
完全に独立した別プロセスだとこうなっちゃうのか……w
ウェイトかけるてのじゃ確実性に欠けるし、動作も遅くなるしなぁ。
あと、コンソールも表示されないのが期待動作だったのだけども、なんでか出てるなと。おなじコンソールアプリのUnifyZipはコンソールでないのになんで?
で、そもそも、思い違いをしてたのが、何も表示されないアプリ作るのって、コンソールアプリじゃなくて普通のwin32アプリを使うのが普通なのですね……。単純にウィンドウを表示しないアプリを作ればよかったのか。
エラーの時はメッセージボックスつかえるので、標準出力とか使わないで良いし。
そんでもって、実行ファイルのサイズも、コンソールアプリだと300kbぐらいだけど、win32の場合は80kbぐらい(vcのランタイムの依存度が高いんだろうな)
なんか、ウィンドウも出さない、極小のプログラムを書くときは、コンソールアプリ。っていう先入観もってたなーと。
で、win32アプリでゴミ箱exeつくってQProcessで実行してみたところ。
普通にstartで期待道理の動作に。ちゃんと終わったら勝手にちゃんとプロセスも終了してくれてるっぽい。
これで晴れてwindows.hの排除に成功~。これまたへんな回り道しちゃったなぁ……。
あとは、レイアウトの見直し。
やっぱ画像のプレビュー画面が小さい。
しかし、今まで使ってた書庫ではなく普通にファイルを追加するタイプの画像編集ソフトでは、設定画面がメニュー→設定で開いて設定して、その画面は閉じたあと、編集後の状況が見えるって感じの作りで。
やっぱ編集設定見ながら、設定適用後のものをみたい。設定変えたら即反映。
ってのがやりやすいなというのがあって、そういうレイアウトにしてたのですが。
プレビュー画面の幅を圧迫しちゃうなーと。
一応画像プレビューは拡大縮小もできるのですが……いかんせん、QGrahicsVeiewの拡大縮小はえらく汚いんですよね。一番クオリティの高いやつえらんでもこれ。アンチェリつけるオプションとかもあるけど、つけても汚い画像がぼやけるだけというありさまw
なので完全にプレビュー専用ですねこれは。
適用後の画像(リサイズ後)なんかは、リサイズ処理した後の画像をQGrahicsVeiewに再設定するので、100%表示のときは、編集結果も普通に綺麗に表示されるから、そこまで気にする物でもないのかもだけど。
この辺は本気で対応しようとするとかなりめんどくさそうぽ……。
でも、やっぱ編集設定画面は表示しつづけたい。
レイアウトの範囲の取り合いになってる感じでどうしたモンかなと。
そこで、編集設定は別窓で表示することに。モードレスな子ウィンドウで。
それなら消したいときにいつでも消せるし、表示場所もサイズも変えられるし。プレビュー画面も大きく取れるようになるし。
んでもって。
実際運用してみて感じたのが、複数の書庫を放り込むと、解析中にかるくハングる。QTは処理待ちで長時間とまると落ちる仕組みになってるらしくQApplication::processEventsをちょいちょいよびだしてイベントを処理してやらないといけないらしい。
が、それで落ちなくなっても、処理待ちの間は応答不能になるので、これもやっぱ別プロセスで読み込み部分は作るべきだなと。
そうすれば読み込みの進行度とかもプログレスバーで表示とか出来るし。
それから登録する書庫ファイルリストはそんな登録しないので良いとして、書庫内のファイルリストを表示する部分は、数十程度なら気にならないけど、数百ファイルとなると、リストの更新がもっさり。
QTableWidgetでなく、QTableViewに変えるべきだろうな。ファイルリストのほうは。
両者の違いは、後者はモデルとビューが別れている、いわゆるMVCってやつですね。なので、データの量がどんだけ増えてもそれほど重くならない。
前者のは、更新の毎に前アイテム構築しなおすので数件とか数十件程度ならそれほど気にならないけど、それ以上になると、かなり厳しいです。
てかこの辺は実のところ、とりあえず今は前者のパターンで。
うまく全体的に動くの出来たら後から置き換えようと思ってた部分ではあるのだけども。
一旦モデルビューにしてしまうと、後からデータ構造の変更とか面倒なので。
先にとりあえず作っちゃってから変更の余地無くなったところで置き換えぐらいが面倒少ないかなというところもあって、残してた部分でもあるのですが。
やっぱ実際に数が増えると重い……。
とかまあ、ちょいちょい修正案も多く。
いつになったら終わるねん。という感じに。
あとはなにげにやっぱファイルサイズがすごいなと。
書庫編集アプリのexe自体は380KBぐらいと、そんなでかくもないのですが(小さくもないけど)
QTのランタイムも含めると、38MBに。
100倍だー!(野沢雅子調)
ちょっと作って配布~ってのにはでかすぎるなぁ(いやいまのところ配布とかする予定もないですけど)
そもQTのランタイムなんて、QT開発やってる人以外のPCにはまずはいってないし。ランタイムのver互換もないので、実行ファイルと同じ場所にランタイム同梱てのが最近は標準っぽいし。
その辺もいまいちQTの普及しない一因なのかなーとか。
そんな感じで、結局1から組み直しとかすることに(ぉ
まず、もう統合アーカイバ系のDLLは最初から使わない方向で。書庫ファイルかどうかのチェックも、アーカイバ内ドキュメントみるに、チェックの強度で、「標準」てのが、ヘッダのチェック。これは多分。localヘッダとcentralヘッダの重複部分のチェックだとおもわれ。これは普通に自前の読み込みルーチンの中でやってる。チェックの一番キツイ奴でも、ヘッダ内のcrc32の項目の値と、圧縮ファイルのcrc32の値を再チェックするという項目が増えるぐらいのもののようで。それは現状自前のではやってないんですけど(ファイルデータからcrc32の値取得するのってどのくらいコスト掛かるのかもよくわかってないってのもあって)とにかく、その辺ももう、自前でやってるんだなとおもうと、もう完全にアーカイバDLLいらんやん。ってことに。
んで、それをパージすることで何が得かというと、windows.hをインクルードしなくて済む用になるということ。
windows.hインクルードすると、大量のdefineマクロが追加されて、名前空間をレイプしやがるので、出来ればしたくないものであります。
vcだとそこまで気にならないのですが、Qt creatorだと、ファックされた名前空間からどばどばと使うあてもない候補が並んで、欲しいものを探すのに苦労する(そうならないように細かく名前空間とか別けてるのに…)のがなんともファッキンです。
で、それでアーカイバDLLつかわなければwindows.hも使わなくていいなーとおもったのですが。もう一個windows.hが必要なもの内部で使ってたのを思い出す。
……ゴミ箱。
ファイルを削除するときに、ゴミ箱にいれるっていうのは、windowsのshellの機能とかなんとかで、windows.hとともにShellAPI.hのインクルードが必要で、そんでまたなんとも使いにくい仕様のSHFileOperationとかいうAPIを使わないと、ゴミ箱にファイルを捨てる事が出来ないという。
で、アーカイバDLLパージしたのに、ゴミ箱の所為で結局windows.h外せないのかよ。とかおもったのですが、そこで、そうかこれ、コマンドラインでファイルパス渡して、渡された物をゴミ箱に放り込むという別アプリにしてしまえばいいのかと。
……windows.h使いたくないだけのために、exeにファイルをドラッグするとファイルがゴミ箱に捨てられるだけのアプリを組むとか、なんだかなぁ……な感じですが。でも今後もQTつかうんならまあ便利かなと言う気も。
で、いざ作ろうと思ったところで。
うまく動かない~。
exeファイル単体にエクスプローラ上でファイルをドロップするときはちゃんと動くんだけど、QT上でQProcessから実行すると、「QProcess: destroyed while process still running」とかでたうえで、ゴミ箱にファイルはいらなーい。
なんかプロセスが終了出来てないのに終了しようとしたよ? ってきなメッセージだとおもうのですが。
コンソールアプリの最後はgetcharでキー入力待ちしてるのだけど、それはcloseWriteChannelというもので回避出来るはずなので、自動でプロセスは終わってるはずなんだけどなぁ……。
QProcessでは別プロセスを開始するのに、startとexecuteそれにstartDetachedと
いうのがあって、startは子プロセスとして。startDetachedは独立したプロセスとして起動するんだとか。executeはstartとなんか違うらしいのですが、サンプルが見つからなかったのでよくわからず。
とりあえずstartDetachedに変えてみたら、コンソールが表示され、ゴミ箱にファイルを送れるようにはなる。
が、なんかおかしい。
動作的には、書庫ファイルの中身編集した結果を、メモリバッファ上にファイルイメージを構築。それが終わったら、元ファイルをゴミ箱にすて、元ファイル名と同じ名前をつけてメモリバッファ上のものをファイルとして保存。
てな感じの上書きプロセスなんだけど、実行してみると、ファイルがゴミ箱に行くだけで、元ファイル名のファイルは保存されてない。
……というか、「上書き保存」の後に「ゴミ箱に捨てる」が実行されてるっぽいw
完全に独立した別プロセスだとこうなっちゃうのか……w
ウェイトかけるてのじゃ確実性に欠けるし、動作も遅くなるしなぁ。
あと、コンソールも表示されないのが期待動作だったのだけども、なんでか出てるなと。おなじコンソールアプリのUnifyZipはコンソールでないのになんで?
で、そもそも、思い違いをしてたのが、何も表示されないアプリ作るのって、コンソールアプリじゃなくて普通のwin32アプリを使うのが普通なのですね……。単純にウィンドウを表示しないアプリを作ればよかったのか。
エラーの時はメッセージボックスつかえるので、標準出力とか使わないで良いし。
そんでもって、実行ファイルのサイズも、コンソールアプリだと300kbぐらいだけど、win32の場合は80kbぐらい(vcのランタイムの依存度が高いんだろうな)
なんか、ウィンドウも出さない、極小のプログラムを書くときは、コンソールアプリ。っていう先入観もってたなーと。
で、win32アプリでゴミ箱exeつくってQProcessで実行してみたところ。
普通にstartで期待道理の動作に。ちゃんと終わったら勝手にちゃんとプロセスも終了してくれてるっぽい。
これで晴れてwindows.hの排除に成功~。これまたへんな回り道しちゃったなぁ……。
あとは、レイアウトの見直し。
やっぱ画像のプレビュー画面が小さい。
しかし、今まで使ってた書庫ではなく普通にファイルを追加するタイプの画像編集ソフトでは、設定画面がメニュー→設定で開いて設定して、その画面は閉じたあと、編集後の状況が見えるって感じの作りで。
やっぱ編集設定見ながら、設定適用後のものをみたい。設定変えたら即反映。
ってのがやりやすいなというのがあって、そういうレイアウトにしてたのですが。
プレビュー画面の幅を圧迫しちゃうなーと。
一応画像プレビューは拡大縮小もできるのですが……いかんせん、QGrahicsVeiewの拡大縮小はえらく汚いんですよね。一番クオリティの高いやつえらんでもこれ。アンチェリつけるオプションとかもあるけど、つけても汚い画像がぼやけるだけというありさまw
なので完全にプレビュー専用ですねこれは。
適用後の画像(リサイズ後)なんかは、リサイズ処理した後の画像をQGrahicsVeiewに再設定するので、100%表示のときは、編集結果も普通に綺麗に表示されるから、そこまで気にする物でもないのかもだけど。
この辺は本気で対応しようとするとかなりめんどくさそうぽ……。
でも、やっぱ編集設定画面は表示しつづけたい。
レイアウトの範囲の取り合いになってる感じでどうしたモンかなと。
そこで、編集設定は別窓で表示することに。モードレスな子ウィンドウで。
それなら消したいときにいつでも消せるし、表示場所もサイズも変えられるし。プレビュー画面も大きく取れるようになるし。
んでもって。
実際運用してみて感じたのが、複数の書庫を放り込むと、解析中にかるくハングる。QTは処理待ちで長時間とまると落ちる仕組みになってるらしくQApplication::processEventsをちょいちょいよびだしてイベントを処理してやらないといけないらしい。
が、それで落ちなくなっても、処理待ちの間は応答不能になるので、これもやっぱ別プロセスで読み込み部分は作るべきだなと。
そうすれば読み込みの進行度とかもプログレスバーで表示とか出来るし。
それから登録する書庫ファイルリストはそんな登録しないので良いとして、書庫内のファイルリストを表示する部分は、数十程度なら気にならないけど、数百ファイルとなると、リストの更新がもっさり。
QTableWidgetでなく、QTableViewに変えるべきだろうな。ファイルリストのほうは。
両者の違いは、後者はモデルとビューが別れている、いわゆるMVCってやつですね。なので、データの量がどんだけ増えてもそれほど重くならない。
前者のは、更新の毎に前アイテム構築しなおすので数件とか数十件程度ならそれほど気にならないけど、それ以上になると、かなり厳しいです。
てかこの辺は実のところ、とりあえず今は前者のパターンで。
うまく全体的に動くの出来たら後から置き換えようと思ってた部分ではあるのだけども。
一旦モデルビューにしてしまうと、後からデータ構造の変更とか面倒なので。
先にとりあえず作っちゃってから変更の余地無くなったところで置き換えぐらいが面倒少ないかなというところもあって、残してた部分でもあるのですが。
やっぱ実際に数が増えると重い……。
とかまあ、ちょいちょい修正案も多く。
いつになったら終わるねん。という感じに。
あとはなにげにやっぱファイルサイズがすごいなと。
書庫編集アプリのexe自体は380KBぐらいと、そんなでかくもないのですが(小さくもないけど)
QTのランタイムも含めると、38MBに。
100倍だー!(野沢雅子調)
ちょっと作って配布~ってのにはでかすぎるなぁ(いやいまのところ配布とかする予定もないですけど)
そもQTのランタイムなんて、QT開発やってる人以外のPCにはまずはいってないし。ランタイムのver互換もないので、実行ファイルと同じ場所にランタイム同梱てのが最近は標準っぽいし。
その辺もいまいちQTの普及しない一因なのかなーとか。
2016-08
28
00:30:10
ようやく一段落
なんだか意外に時間がかかってしまった、書庫編集ツール。
とりあえず一区切りついたかなと。
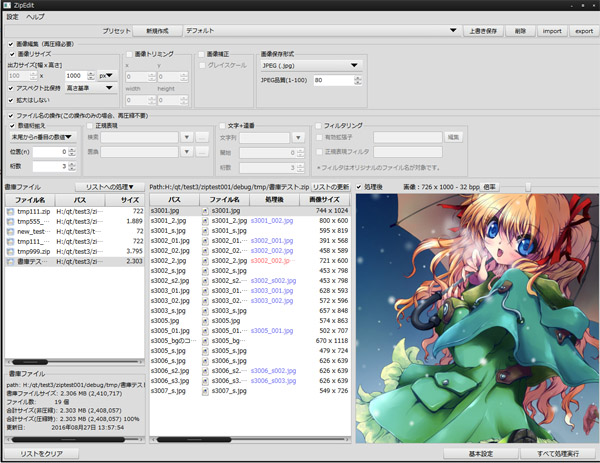
一時ファイルに解凍とかしないで、直接画像をリサイズやフォーマット変更等の加工(非圧縮書庫限定)
zip書庫の再圧縮なしのファイル一括リネーム(正規表現置換、連番、桁合わせ)、ファイルの個別削除。
リネームと削除は圧縮書庫でもそのまま可能かつ、再圧縮しないので一瞬で終わる。
あとは画像のフォーマットやサイズの一覧表示とかできる、書庫内のそこそこ高速な閲覧。
てな感じなのようやく出来。
やっぱいちいち書庫とか解凍してから、画像編集とかタルイので、このツールでいろいろ一本化できそう。実際には人様の作ったツール(UnifyZip)のサポートありきなかんじですが。
フォルダ回りの走査が超めんどいので……。
ファイルの一覧&編集結果表示とかしたかったのでテーブルリスト表示にしたのだけども、フォルダ構造表示するのにはふつうツリービューですよね。
でもツリービューだと編集結果とか一度に表示出来なかったりとか、一括で編集とかやるの考えると、一本のリストで完結したい。そこで再帰的な走査が必要になるフォルダ構造とか超邪魔w
ってことで、非圧縮書庫化の他にも、余計なフォルダの除去とかでもUnifyZipのお世話に。データ構造の相性的にフォルダの除去機能とかつけるのめんどい感じになっちゃったので。
しかし、一番の感想は……。
zipフォーマットは酷いフォーマットだなと。
歴史的経緯というのもおおきいのだろうけど、とにかく統一性が無いというところがうっとうしいですね。唯一の救いは、フォーマットの情報がネットでいくらでも出てくると言うところか(古い情報に惑わされる事もあるけど)
なにげに日本語混じりのファイル名かフォルダか含むと? winrarで作ったzipでは、Info-Zipとやらが提唱した、unicode文字をファイル名に使う拡張が埋め込まれるっぽい。けどぐぐってみると、提唱もと自体がもう使ってないとか。なんだそりゃw
そんでもって、この拡張がある場合は、zipファイルのヘッダのなかにあるオプションフラグにも、unicodeフラグというものがあるのだけど、このInfo-Zip拡張の場合はこのフラグはoffのままだったり、はたまた基本的にzipのなかのファイル名などの文字コードは、作成環境のローカルの文字セットが使われるという仕様らしく、unix系osで作成したzipはunicodeフラグ有る無しにutf-8が使用されるとか。(win系では暗黙でshift-jisがつかわれる)
なので、ヘッダの中の作成OSの種類の値をみて、unicodeか判定するソフトもあるそうな。
個人的には、もうみんなutf-8で統一してほしい感じなのだけども、まだまだwin系のアーカイバでは、古いソフトになるとunicodeには対応して無かったりするし。未だにぼちぼち使ってる画像ビューワのmangameeya(いまだにコレを越えるのがない……)も開発停止してから長く、unicode文字だと化ける~。
て感じなので、unicodeフラグon、Info-Zipのunicode拡張、作成osがunixの時はうにこーどとして読み込みまではまあ簡単。そこから、書庫を保存するときにどうするか……結局現時点のwin上では、保存時は常に文字列はshift-jisで保存するというのが一番トラブル少ないぽか。
いまだにshift-jisの呪縛から逃れ慣れないのか…開発環境まわりはもうすべてutf-8で統一してるんですけどね……。
てか、保存するときは自分でどのオプションとか、拡張機能使うかとか選択肢あるのですが、そのへんみんなばっさりカットで、書き出し部分は非常にシンプルにしてみたり。(というかいろんな他のアーカイバで読める用にするには結局最小構成にするのが一番ぽ)
逆に読み込み部分は、いろいろなフォーマットでも読める用にと、いろいろとちまちま組むハメになってそこいらへんで、zipフォーマットのくそっぷりが身にしみるぅ。
あとは……手前味噌ながら普通に速い。
QTのQDataStreamとからへんが優秀なのか、その辺の書庫系ソフトにくらべて、書庫の読み書きがすんごく速くてびくり。
……てかこれって、unzip32とかの統合アーカイバ系のハンドル取得して検索して回すAPIあたりが腐ってるんじゃないのかな。文字通り。
この辺って、それこそMS-DOSとか、win95とか、メモリが640KBとか8MBとかそんな時代からあるフォーマットやアーカイバのライブラリだし。読み込みも一括でメモリに展開とか贅沢な事も出来なかった頃の仕様が、いまだにそのまま残ってるんじゃなかろうか。
なので、普通に今風の組み方で直接バイナリから読んでると、明らかに速度差が出てるんじゃなかろうか。
そんでもって、あまりにもzipのフォーマットって無駄が多いし、雑多な拡張の所為でカオスだし。
基本的には、胆の部分はファイルの圧縮アルゴリズムの部分で、それ以外の部分はいかようにも組める感じなのに、そこがひたすらあほらしいフォーマットになってるのはなんだかなぁと。
でもこういうのって、結局何が流行るかわかんないし、そして流行った物勝ちで、内部構造がどうだとか、圧縮率がどうだとか、性能部分が秀でてるものが天下とるとは限らないんですよね。
そんなかんじで、漠然と最初は書庫を読むってと統合アーカイバ系のDLLを使うものらしいという先入観あったせいでその方法から入ったのですが、そもそのDLLの内部実装自体が前時代的に古すぎて、結局使わないという結果に。
それで一週間ぐらい時間無駄にしたなぁ……。
アーカイバのDLL関係って、基本的には、一括全解凍、全圧縮と、かなりおおざっぱな機能しかないんですよね。
なので細かいことをやろうと思うと結局自前でバイナリからフォーマット解析して読むしかなく、結局アーカイバDLL関係の仕様は全部破棄して、1からzipのフォーマットの解析作業に。
……当初はほんと、DLL読み込んだらもう書庫回りのことは大抵のことは出来ちゃうもんだとおもってたですよ(遠い目…・・)
ああ、そういえば、jpegのExifまわりも余計な回り道だったなぁ……。結局調べたことはほとんどなんにも使わなかったものなw
とにかくなんか無駄が多い感じだったな今回。
かるーく一週間ぐらいで作る予定だったのに……。
そんな感じで、最後はやっぱり愚痴っぽく。……いかんな。
とりあえず、ここ数日実際にいろんな書庫にたいして使ってみて、運用テストしてるのですが、意外に良い感じに使えているぽ。
読めないものごくたまにあるんですが、そのファイルはUnifyZipでもエラーになったりして、これは邪魔くさい。
そのファイルのフォーマットどうなってるのか調べるかーってところでモチベーションが切れたぽ。
とりあえず、根詰めて組むのはもう終わりにして、あとはちょいちょい運用しながらバグフィックスしていく感じにしていこうかと。
やはり、実戦こそが最高のテストdeathね。
ついでにちょっとまえに計測してみたので、一段落ついた今の状態でも計測してみたり。
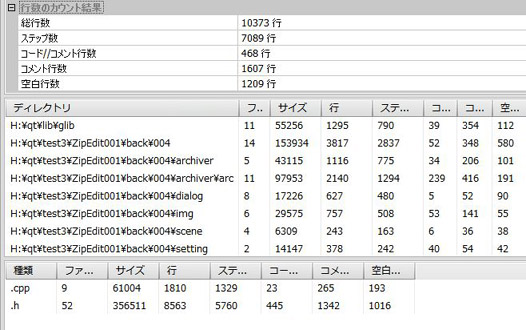
先週の段階で4000ステップぐらいで、今回は7000ステップ。
3000しか増えてないやん。まあ、今週はコード書くよりもテストの方が時間食ってたので、こんな物か。
はーちかれた。
とりあえず一区切りついたかなと。
一時ファイルに解凍とかしないで、直接画像をリサイズやフォーマット変更等の加工(非圧縮書庫限定)
zip書庫の再圧縮なしのファイル一括リネーム(正規表現置換、連番、桁合わせ)、ファイルの個別削除。
リネームと削除は圧縮書庫でもそのまま可能かつ、再圧縮しないので一瞬で終わる。
あとは画像のフォーマットやサイズの一覧表示とかできる、書庫内のそこそこ高速な閲覧。
てな感じなのようやく出来。
やっぱいちいち書庫とか解凍してから、画像編集とかタルイので、このツールでいろいろ一本化できそう。実際には人様の作ったツール(UnifyZip)のサポートありきなかんじですが。
フォルダ回りの走査が超めんどいので……。
ファイルの一覧&編集結果表示とかしたかったのでテーブルリスト表示にしたのだけども、フォルダ構造表示するのにはふつうツリービューですよね。
でもツリービューだと編集結果とか一度に表示出来なかったりとか、一括で編集とかやるの考えると、一本のリストで完結したい。そこで再帰的な走査が必要になるフォルダ構造とか超邪魔w
ってことで、非圧縮書庫化の他にも、余計なフォルダの除去とかでもUnifyZipのお世話に。データ構造の相性的にフォルダの除去機能とかつけるのめんどい感じになっちゃったので。
しかし、一番の感想は……。
zipフォーマットは酷いフォーマットだなと。
歴史的経緯というのもおおきいのだろうけど、とにかく統一性が無いというところがうっとうしいですね。唯一の救いは、フォーマットの情報がネットでいくらでも出てくると言うところか(古い情報に惑わされる事もあるけど)
なにげに日本語混じりのファイル名かフォルダか含むと? winrarで作ったzipでは、Info-Zipとやらが提唱した、unicode文字をファイル名に使う拡張が埋め込まれるっぽい。けどぐぐってみると、提唱もと自体がもう使ってないとか。なんだそりゃw
そんでもって、この拡張がある場合は、zipファイルのヘッダのなかにあるオプションフラグにも、unicodeフラグというものがあるのだけど、このInfo-Zip拡張の場合はこのフラグはoffのままだったり、はたまた基本的にzipのなかのファイル名などの文字コードは、作成環境のローカルの文字セットが使われるという仕様らしく、unix系osで作成したzipはunicodeフラグ有る無しにutf-8が使用されるとか。(win系では暗黙でshift-jisがつかわれる)
なので、ヘッダの中の作成OSの種類の値をみて、unicodeか判定するソフトもあるそうな。
個人的には、もうみんなutf-8で統一してほしい感じなのだけども、まだまだwin系のアーカイバでは、古いソフトになるとunicodeには対応して無かったりするし。未だにぼちぼち使ってる画像ビューワのmangameeya(いまだにコレを越えるのがない……)も開発停止してから長く、unicode文字だと化ける~。
て感じなので、unicodeフラグon、Info-Zipのunicode拡張、作成osがunixの時はうにこーどとして読み込みまではまあ簡単。そこから、書庫を保存するときにどうするか……結局現時点のwin上では、保存時は常に文字列はshift-jisで保存するというのが一番トラブル少ないぽか。
いまだにshift-jisの呪縛から逃れ慣れないのか…開発環境まわりはもうすべてutf-8で統一してるんですけどね……。
てか、保存するときは自分でどのオプションとか、拡張機能使うかとか選択肢あるのですが、そのへんみんなばっさりカットで、書き出し部分は非常にシンプルにしてみたり。(というかいろんな他のアーカイバで読める用にするには結局最小構成にするのが一番ぽ)
逆に読み込み部分は、いろいろなフォーマットでも読める用にと、いろいろとちまちま組むハメになってそこいらへんで、zipフォーマットのくそっぷりが身にしみるぅ。
あとは……手前味噌ながら普通に速い。
QTのQDataStreamとからへんが優秀なのか、その辺の書庫系ソフトにくらべて、書庫の読み書きがすんごく速くてびくり。
……てかこれって、unzip32とかの統合アーカイバ系のハンドル取得して検索して回すAPIあたりが腐ってるんじゃないのかな。文字通り。
この辺って、それこそMS-DOSとか、win95とか、メモリが640KBとか8MBとかそんな時代からあるフォーマットやアーカイバのライブラリだし。読み込みも一括でメモリに展開とか贅沢な事も出来なかった頃の仕様が、いまだにそのまま残ってるんじゃなかろうか。
なので、普通に今風の組み方で直接バイナリから読んでると、明らかに速度差が出てるんじゃなかろうか。
そんでもって、あまりにもzipのフォーマットって無駄が多いし、雑多な拡張の所為でカオスだし。
基本的には、胆の部分はファイルの圧縮アルゴリズムの部分で、それ以外の部分はいかようにも組める感じなのに、そこがひたすらあほらしいフォーマットになってるのはなんだかなぁと。
でもこういうのって、結局何が流行るかわかんないし、そして流行った物勝ちで、内部構造がどうだとか、圧縮率がどうだとか、性能部分が秀でてるものが天下とるとは限らないんですよね。
そんなかんじで、漠然と最初は書庫を読むってと統合アーカイバ系のDLLを使うものらしいという先入観あったせいでその方法から入ったのですが、そもそのDLLの内部実装自体が前時代的に古すぎて、結局使わないという結果に。
それで一週間ぐらい時間無駄にしたなぁ……。
アーカイバのDLL関係って、基本的には、一括全解凍、全圧縮と、かなりおおざっぱな機能しかないんですよね。
なので細かいことをやろうと思うと結局自前でバイナリからフォーマット解析して読むしかなく、結局アーカイバDLL関係の仕様は全部破棄して、1からzipのフォーマットの解析作業に。
……当初はほんと、DLL読み込んだらもう書庫回りのことは大抵のことは出来ちゃうもんだとおもってたですよ(遠い目…・・)
ああ、そういえば、jpegのExifまわりも余計な回り道だったなぁ……。結局調べたことはほとんどなんにも使わなかったものなw
とにかくなんか無駄が多い感じだったな今回。
かるーく一週間ぐらいで作る予定だったのに……。
そんな感じで、最後はやっぱり愚痴っぽく。……いかんな。
とりあえず、ここ数日実際にいろんな書庫にたいして使ってみて、運用テストしてるのですが、意外に良い感じに使えているぽ。
読めないものごくたまにあるんですが、そのファイルはUnifyZipでもエラーになったりして、これは邪魔くさい。
そのファイルのフォーマットどうなってるのか調べるかーってところでモチベーションが切れたぽ。
とりあえず、根詰めて組むのはもう終わりにして、あとはちょいちょい運用しながらバグフィックスしていく感じにしていこうかと。
やはり、実戦こそが最高のテストdeathね。
ついでにちょっとまえに計測してみたので、一段落ついた今の状態でも計測してみたり。
先週の段階で4000ステップぐらいで、今回は7000ステップ。
3000しか増えてないやん。まあ、今週はコード書くよりもテストの方が時間食ってたので、こんな物か。
はーちかれた。
2016-08
23
03:06:01
ずるずる
まだ書庫内ファイル変換PGやってたり。
なんかいろいろと横道にそれたりしてるもんだから……。
結局、jpgのExif情報は、なんだかんだで要らないデータだという結論に。
そも、QImageで読み込んで、変換とかした上で再保存すると、Exif情報は吹っ飛ぶのがデフォなので。そして、もともとExif情報は除去したい方向なのと、jpg限定なので、わざわざ読み込んでも利用価値とかないなと。読み書きでExif情報を保持しつづけたいというのでもなければ、もともと必要もないものだし。
でも、非圧縮な書庫の場合は、ファイルデータがそのまま入ってるので、ヘッダを読む事は可能ということで、画像のサイズ(width,height)と色数、ビット深度ぐらいは取得するかーということで、jpegのその情報とるのにも、結局たくさんあるヘッダ情報のなかから取捨選択するのに、結局それなりにヘッダの構造の知識はいったので、まあ結果オーライか。てか、ひちめんどくさいフォーマットになってるのですね……jpgって。
それに引き替え、bmpやpngのフォーマットの簡素なこと。わかりやすくて良いです。
てか、bmpのヘッダなんか久しぶりにのぞいたよ……大昔の、HTでαブレンディングとかやってた時代を思い出すにょう。
昔は自前でピクセル見て透過処理とかやてったんですよね。なのでピクセルデータがベタで入ってるbmpファイルが使われたので。
なにげに微妙に嵌ったのが、bmpやpngのヘッダのなかの画像の大きさのデータはwidth、heightの順番に格納されているのだけども、なぜかjpgはheight,widthの順番に格納されてるぽ。なので、情報取得してリストで表示してる時に、あれ? 幅のサイズがおかしい?? と一瞬混乱したw うーん。jpgめんどくせぇ。
んで、ようやく最後の仕上げ、変換後の書庫ファイル書き出し部分。
とりあえずテストでQImageで読み込んだ画像をメモリ上のバッファに保存。そのバッファをつかって、その画像一枚だけ入ってる非圧縮zipファイルをバイナリから作ってみるテストを別プロジェクト立ち上げて作ってみることに。
……そうか、zipに登録するファイルって、crc32の値がいるのか。
いまだにc++って、標準でcrc32を算出するのないんだよな。他の言語ではぼちぼちはいってるのに。
が、QTなら、とおもったんだけども、QTにもはいってなひ……。
結局自前で(つーてもほとんどwebサイトで見つかったコードをQT用に書き直しただけ)実装。
で、zip出力。
「CRCエラー」
あるぇー? _| ̄|○
Explzhで中身を見てみると、追加した画像ファイルは認識してるっぽい。
ファイルのcrc32の値も、にバイナリ化したQImageのデータを一旦またjpgにして保存したファイルを、普通の圧縮ソフトでzip化したものの中のファイルのcrc32の値と同値。
crc32の算出が間違っているわけでもないぽ。でもなんで「CRCエラー」??
書庫内ファイルも開けないし。
Explzhの「修復」を行ってみる。
したら普通に利用可能な書庫になる。
んで、バイナリエディタで、修復前と後を比較してみると……。
んん?
なんでか修復後のファイル、CentralDirectoryHeader部の対応するLocalFileHeaderまでのオフセットが変な値になってる。
ここは、ファイルは一つしかないのでファイルの先頭、0になってるはずなんだけど。
でも書庫ファイルは開けてるので、問題はここじゃない。
うーん。
結果的には、書庫の一番末尾につけるEndOfCentralDirectoryRecord内の1フィールドのサイズが一個、2バイトのところを4バイトにしちゃってたところがあったというオチで、そこ直したら普通にzipとして認識されたりしてw EndOfCentralDirectoryRecordのサイズがおかしかったのですね。普通に書庫内の画像も閲覧出来る用に。
でもそれでなんでCRC32エラー?
あと、修復後のファイルのほうの、LocalFileHeaderまでのオフセットが異常値でもzipファイルとしては問題無いってのも不思議。
てかこの値、普通に使ってないんだろうな……。
ファイルの構造的に、先頭からLocalFileHeader読んでったとき、のときにLocalFileHeaderの開始位置オフセットも取得しながら読んでいくのだけど、それはCentralDirectoryHeaderにLocalFileHeaderのオフセットを書き込むフィールドがあるからと言う理由で。順序が逆だw
なので、このオフセット値ってそもつかわないんだよな。
本来はファイル末尾のEndOfCentralDirectoryRecordから読みこんで、その中の
CentralDirectoryHeaderの開始位置オフセット読み込んで、そこからCentralDirectoryHeader内のLocalFileHeaderの情報を読んでいくという構想だったのだろうけど……。
EndOfCentralDirectoryRecordの末尾に可変長のデータがあることと、いろいろほかにも拡張データとか引っ付いてたりするので、末尾からEndOfCentralDirectoryRecordの先頭を探すのは確実性が低い(拡張データとかのなかに、偶然ヘッダの開始シグネイチャと同じ並びのバイナリがないともかぎらないので)
結局この方法の読み込みは現実的ではなく、結局先頭から読んでいく形になると、LocalFileHeaderのオフセットいらないんですよね。
そんなかんじなので、CentralDirectoryHeaderも、LocalFileHeaderと重複してるデータ部を比較して正当性チェックのためにあるようなもので、本来の収録ファイルのインデックスヘッダ的な役割をはなせないでいるぽ。
なので、LocalFileHeaderへのオフセットは正当性チェックにも使われないので変な値がはいっててもスルーと言うことなのだろうかw
でも、EndOfCentralDirectoryRecordから逆引きするような展開方法をとっているアーカイバだと、エラーになる可能性がある状態でもあるし。
いろいろと難儀なフォーマットだな……zipって。
とにかく、あとちょっとで終わるぽ。
なんか、あとちょっとってところから結構時間かかっちゃってるなぁ。
関係無い調べ物とかに没頭してたりと、脱線が多い……。
あとは、微妙な嵌りポイントがいくつか。
QTableWidgetのリスト内を、右クリックした状態でドラッグして離すと、コンテキストメニュー呼び出すイベント内で取得出来るリストのindex値は、クリック開始時でなく離した位置のindex値になること。
その場合、リストのcurrentIndexは変更されないので、クリック→currentIndex取得してリストのデータにアクセスみたいな事やってると嵌るぽ。
それに離した位置のindex取得って挙動も違和感あるなぁ……。
それからQTのシグナルとスロットの機構、へんな嵌りポイントがあるぽ。
どうみてもコレであってる筈なのに、No such signal とか抜かしやがるファッキン! とおもってたら、どうやらシグナル名が、どこぞの知らないところですでに使われている名前だったらしく、それでエラーになってたっぽい。
この辺、いろいろ多重継承されてるオブジェクトおおいので、どの名前が使用不可とかよくわからんし、名前の重複が想像できるようなエラーも出ないので嵌るわー。
あとは、どうも最近のQT creatorの挙動が不安定。
ソース変更してても変更部分のビルドが不完全で以前のコードの部分が残ってるかんじで、しょっちゅうリビルド必要ぽ。プリコンパイラ涙目(ぉ
あとui関係追加すると、qmake必要になるっぽい?
この辺はmsvcビルドだからとかあるのかな??
そんな感じで、なんでうごかんのじゃーとおもったらリビルド一発で治ったり、一旦クリーンしてqmakeしてリビルドしたら治ったりとか、コードのバグ以外の所でのエラーに泣かされること多い。
むうう。
なんかいろいろと横道にそれたりしてるもんだから……。
結局、jpgのExif情報は、なんだかんだで要らないデータだという結論に。
そも、QImageで読み込んで、変換とかした上で再保存すると、Exif情報は吹っ飛ぶのがデフォなので。そして、もともとExif情報は除去したい方向なのと、jpg限定なので、わざわざ読み込んでも利用価値とかないなと。読み書きでExif情報を保持しつづけたいというのでもなければ、もともと必要もないものだし。
でも、非圧縮な書庫の場合は、ファイルデータがそのまま入ってるので、ヘッダを読む事は可能ということで、画像のサイズ(width,height)と色数、ビット深度ぐらいは取得するかーということで、jpegのその情報とるのにも、結局たくさんあるヘッダ情報のなかから取捨選択するのに、結局それなりにヘッダの構造の知識はいったので、まあ結果オーライか。てか、ひちめんどくさいフォーマットになってるのですね……jpgって。
それに引き替え、bmpやpngのフォーマットの簡素なこと。わかりやすくて良いです。
てか、bmpのヘッダなんか久しぶりにのぞいたよ……大昔の、HTでαブレンディングとかやってた時代を思い出すにょう。
昔は自前でピクセル見て透過処理とかやてったんですよね。なのでピクセルデータがベタで入ってるbmpファイルが使われたので。
なにげに微妙に嵌ったのが、bmpやpngのヘッダのなかの画像の大きさのデータはwidth、heightの順番に格納されているのだけども、なぜかjpgはheight,widthの順番に格納されてるぽ。なので、情報取得してリストで表示してる時に、あれ? 幅のサイズがおかしい?? と一瞬混乱したw うーん。jpgめんどくせぇ。
んで、ようやく最後の仕上げ、変換後の書庫ファイル書き出し部分。
とりあえずテストでQImageで読み込んだ画像をメモリ上のバッファに保存。そのバッファをつかって、その画像一枚だけ入ってる非圧縮zipファイルをバイナリから作ってみるテストを別プロジェクト立ち上げて作ってみることに。
……そうか、zipに登録するファイルって、crc32の値がいるのか。
いまだにc++って、標準でcrc32を算出するのないんだよな。他の言語ではぼちぼちはいってるのに。
が、QTなら、とおもったんだけども、QTにもはいってなひ……。
結局自前で(つーてもほとんどwebサイトで見つかったコードをQT用に書き直しただけ)実装。
で、zip出力。
「CRCエラー」
あるぇー? _| ̄|○
Explzhで中身を見てみると、追加した画像ファイルは認識してるっぽい。
ファイルのcrc32の値も、にバイナリ化したQImageのデータを一旦またjpgにして保存したファイルを、普通の圧縮ソフトでzip化したものの中のファイルのcrc32の値と同値。
crc32の算出が間違っているわけでもないぽ。でもなんで「CRCエラー」??
書庫内ファイルも開けないし。
Explzhの「修復」を行ってみる。
したら普通に利用可能な書庫になる。
んで、バイナリエディタで、修復前と後を比較してみると……。
んん?
なんでか修復後のファイル、CentralDirectoryHeader部の対応するLocalFileHeaderまでのオフセットが変な値になってる。
ここは、ファイルは一つしかないのでファイルの先頭、0になってるはずなんだけど。
でも書庫ファイルは開けてるので、問題はここじゃない。
うーん。
結果的には、書庫の一番末尾につけるEndOfCentralDirectoryRecord内の1フィールドのサイズが一個、2バイトのところを4バイトにしちゃってたところがあったというオチで、そこ直したら普通にzipとして認識されたりしてw EndOfCentralDirectoryRecordのサイズがおかしかったのですね。普通に書庫内の画像も閲覧出来る用に。
でもそれでなんでCRC32エラー?
あと、修復後のファイルのほうの、LocalFileHeaderまでのオフセットが異常値でもzipファイルとしては問題無いってのも不思議。
てかこの値、普通に使ってないんだろうな……。
ファイルの構造的に、先頭からLocalFileHeader読んでったとき、のときにLocalFileHeaderの開始位置オフセットも取得しながら読んでいくのだけど、それはCentralDirectoryHeaderにLocalFileHeaderのオフセットを書き込むフィールドがあるからと言う理由で。順序が逆だw
なので、このオフセット値ってそもつかわないんだよな。
本来はファイル末尾のEndOfCentralDirectoryRecordから読みこんで、その中の
CentralDirectoryHeaderの開始位置オフセット読み込んで、そこからCentralDirectoryHeader内のLocalFileHeaderの情報を読んでいくという構想だったのだろうけど……。
EndOfCentralDirectoryRecordの末尾に可変長のデータがあることと、いろいろほかにも拡張データとか引っ付いてたりするので、末尾からEndOfCentralDirectoryRecordの先頭を探すのは確実性が低い(拡張データとかのなかに、偶然ヘッダの開始シグネイチャと同じ並びのバイナリがないともかぎらないので)
結局この方法の読み込みは現実的ではなく、結局先頭から読んでいく形になると、LocalFileHeaderのオフセットいらないんですよね。
そんなかんじなので、CentralDirectoryHeaderも、LocalFileHeaderと重複してるデータ部を比較して正当性チェックのためにあるようなもので、本来の収録ファイルのインデックスヘッダ的な役割をはなせないでいるぽ。
なので、LocalFileHeaderへのオフセットは正当性チェックにも使われないので変な値がはいっててもスルーと言うことなのだろうかw
でも、EndOfCentralDirectoryRecordから逆引きするような展開方法をとっているアーカイバだと、エラーになる可能性がある状態でもあるし。
いろいろと難儀なフォーマットだな……zipって。
とにかく、あとちょっとで終わるぽ。
なんか、あとちょっとってところから結構時間かかっちゃってるなぁ。
関係無い調べ物とかに没頭してたりと、脱線が多い……。
あとは、微妙な嵌りポイントがいくつか。
QTableWidgetのリスト内を、右クリックした状態でドラッグして離すと、コンテキストメニュー呼び出すイベント内で取得出来るリストのindex値は、クリック開始時でなく離した位置のindex値になること。
その場合、リストのcurrentIndexは変更されないので、クリック→currentIndex取得してリストのデータにアクセスみたいな事やってると嵌るぽ。
それに離した位置のindex取得って挙動も違和感あるなぁ……。
それからQTのシグナルとスロットの機構、へんな嵌りポイントがあるぽ。
どうみてもコレであってる筈なのに、No such signal とか抜かしやがるファッキン! とおもってたら、どうやらシグナル名が、どこぞの知らないところですでに使われている名前だったらしく、それでエラーになってたっぽい。
この辺、いろいろ多重継承されてるオブジェクトおおいので、どの名前が使用不可とかよくわからんし、名前の重複が想像できるようなエラーも出ないので嵌るわー。
あとは、どうも最近のQT creatorの挙動が不安定。
ソース変更してても変更部分のビルドが不完全で以前のコードの部分が残ってるかんじで、しょっちゅうリビルド必要ぽ。プリコンパイラ涙目(ぉ
あとui関係追加すると、qmake必要になるっぽい?
この辺はmsvcビルドだからとかあるのかな??
そんな感じで、なんでうごかんのじゃーとおもったらリビルド一発で治ったり、一旦クリーンしてqmakeしてリビルドしたら治ったりとか、コードのバグ以外の所でのエラーに泣かされること多い。
むうう。
2016-08
19
05:43:20
一難去ってまた一難……
今日もニコニコPG……。
あとはもう変換して保存するだけな所まできたのだけども。
画像のexifデータの読み取りが……。
てっきりQImageの
QImage img(filepath);
for(const auto& v: img->textKeys()){
list.insert(v, img->text(v));
}
これでタグ名と値のデータ取れるような物だと思ってたのだけど、全然ちがうっぽいw
ていうか、そうならtextKeysで取れる文字はどっからどこに存在する何なのかさぱーり。
で、ググってみるとQExifImageHeaderなるものが。
QList<ExifExtendedTag> extendedTags () const
QList<GpsTag> gpsTags () const
QList<ImageTag> imageTags () const
なんていう便利そうなメソッドもある。
じゃあ、楽ちんジャンとおもったら、QExifImageHeaderが見つからないとか抜かしやがるデスよ。
……なんか拡張ライブラリのなかにあるらしい? で、そいつはGNUライセンスで商用向けっぽいかんじで。
画像のExifデータとか確かに商用ソフトだと必要になりそうな機能だものねっ。
ってことか、ふぁっきんふぁっきん。
で、zipのフォーマットの次はjpegのフォーマット解析が始まるのですかね。
なんか次から次へと面倒が。
車輪の再発明てきに、他のライブラリとか使えない物かとググってみると、win限定ならGDI+のなかにjpegからexif情報取れるらしい。
んーサンプルコード見たところ、かなり低レベル。値だけ取れるだけで、タグの種類とかは自前で把握しているの前提な感じ。もっと抽象化されたような物は無いのかね。
ほかには、Imagemagickでも出来る。こっちはperlではなじみのあるライブラリだけど、c++だとまずインスコしたりとかがめんどくさいなーと……。
使いやすさ的にはこっちのが遙かに楽そうではあるのだけども。
でもそもそもの目的はというと、実際の処理とはあんま関係無く、exif情報も表示するぜってだけの所なんだよなぁ。
あと、QImageで開いて、別名でファイルに保存するとexif情報は綺麗さっぱり消えて無くなるぽ。
なので、除去する処理は必要無いっぽい……って事もないか……。
バイナリで書庫ファイルから読み込んだ画像を編集して、バイナリで書き出す場合、exifとかのヘッダ情報はそのままになるぽ。
なのでやっぱヘッダ情報の除去も自前で書くしかないのかな。
むふう。
あとはもう変換して保存するだけな所まできたのだけども。
画像のexifデータの読み取りが……。
てっきりQImageの
QImage img(filepath);
for(const auto& v: img->textKeys()){
list.insert(v, img->text(v));
}
これでタグ名と値のデータ取れるような物だと思ってたのだけど、全然ちがうっぽいw
ていうか、そうならtextKeysで取れる文字はどっからどこに存在する何なのかさぱーり。
で、ググってみるとQExifImageHeaderなるものが。
QList<ExifExtendedTag> extendedTags () const
QList<GpsTag> gpsTags () const
QList<ImageTag> imageTags () const
なんていう便利そうなメソッドもある。
じゃあ、楽ちんジャンとおもったら、QExifImageHeaderが見つからないとか抜かしやがるデスよ。
……なんか拡張ライブラリのなかにあるらしい? で、そいつはGNUライセンスで商用向けっぽいかんじで。
画像のExifデータとか確かに商用ソフトだと必要になりそうな機能だものねっ。
ってことか、ふぁっきんふぁっきん。
で、zipのフォーマットの次はjpegのフォーマット解析が始まるのですかね。
なんか次から次へと面倒が。
車輪の再発明てきに、他のライブラリとか使えない物かとググってみると、win限定ならGDI+のなかにjpegからexif情報取れるらしい。
んーサンプルコード見たところ、かなり低レベル。値だけ取れるだけで、タグの種類とかは自前で把握しているの前提な感じ。もっと抽象化されたような物は無いのかね。
ほかには、Imagemagickでも出来る。こっちはperlではなじみのあるライブラリだけど、c++だとまずインスコしたりとかがめんどくさいなーと……。
使いやすさ的にはこっちのが遙かに楽そうではあるのだけども。
でもそもそもの目的はというと、実際の処理とはあんま関係無く、exif情報も表示するぜってだけの所なんだよなぁ。
あと、QImageで開いて、別名でファイルに保存するとexif情報は綺麗さっぱり消えて無くなるぽ。
なので、除去する処理は必要無いっぽい……って事もないか……。
バイナリで書庫ファイルから読み込んだ画像を編集して、バイナリで書き出す場合、exifとかのヘッダ情報はそのままになるぽ。
なのでやっぱヘッダ情報の除去も自前で書くしかないのかな。
むふう。
2016-08
17
05:55:41
見間違え……
今日も相変わらずPG。
昨日は脱線して、QTの機能のラッパークラスとかつくってるだけで終わってしまったり。QSettingsまわり、結構ごちゃごちゃ描かなくちゃいけない部分を、もっと楽に書けるようなの作ったりとか。
んで今日はもとの書庫回り関係。
ようやっと最後の書庫回りの実際の解凍やら再圧縮やら保存まわりに着手。
したら衝撃の事実が。
int WINAPI UnZipExtractMem(const HWND hWnd,LPCSTR szCmdLine……
(つд⊂)ゴシゴシ→(;゚ Д゚)HWNDってなんやっ!?
えーと、書庫開いたときに取得するHARCという書庫のハンドルを渡して、そこ経由で書庫内ファイルをメモリ上に展開する関数だと思ってたんですが、ハンドル指定がウィンドウハンドルになってる。
つまり、これ書庫全体をメモリ上に展開する機能だったのですね……。
欲しかったのは書庫内ファイルを単体でメモリ上に展開する機能だったのに……。
なので、結局書庫内ファイル単体解凍は、ファイルにしか書き出せない模様。
メモリ上に展開した画像ファイルなんかはそのままQImageに変換できるので、いちいちテンポラリにファイル書き出さなくて済む……筈だったのにっ。
むうう。
そこでまた方向転換。
基本的には、書庫内ファイルのファイル名のリネームや削除は問題無いとして(中のファイルが圧縮されてようが無かろうが、格納ファイルサイズ分取得して右から左にコピーするだけなので)書庫内の画像ファイルをどうこうするのに、書庫内ファイル単体で解凍する機能が欲しかったわけで。
そうなると、もとから非圧縮な書庫だと問題解決なんですよね。
そこでさらに、先日の日記でも触れた「UnifyZip」というソフト。
書庫形式をrar、lzh等からzipに統一、余分なフォルダ除去、書庫内ファイルのフィルタリング(気づいたら勝手に混入されてたりするサムネキャッシュのThumbs.dbとか除去)圧縮率も統一で、さらには書庫内のファイルの格納順の再ソートもやってくれる物なのですが、これって、コマンドラインツールなんですよね。なので、アプリから、処理するファイルのリストを登録して実行てのを丸投げできるんですよね。
そこで、ドラッグ&ドロップで登録された書庫を、そのリスト内で非圧縮でない書庫ファイルを全部、UnifyZipに送る。という機能を追加したら問題解決だなと。
それ以降の処理は、非圧縮な書庫のみ限定にして。
そもメインは画像系。それも大抵はjpgとかzipで圧縮しても98%とか99%にしかならない、サイズは変わらず読み込みだけは遅くなるという感じで、もともと圧縮する意味ない類の書庫ファイルをどうこうするのが主な目的なので。
そうなると後の処理が非常に楽ちん。
もともとunzip32.dllとかのアーカイバ系は、書庫内ファイルの個別処理には向いてない作りだし。
非圧縮ならバイナリで直接書庫ファイルを弄りほうだい、書庫内ファイルも取得し放題、編集も思いのまま。
これで、アーカイバの書庫内ハンドルつかって検索&処理という、なんだかこれ内部実装てきに速度とかどうなん? といまいち微妙かつ使いづらい(C言語ベースだし)ものも触らなくて済むなと。
そんな感じで、もうちょっと。
そろそろ実のところ飽きてきてます(ぉ
昨日は脱線して、QTの機能のラッパークラスとかつくってるだけで終わってしまったり。QSettingsまわり、結構ごちゃごちゃ描かなくちゃいけない部分を、もっと楽に書けるようなの作ったりとか。
んで今日はもとの書庫回り関係。
ようやっと最後の書庫回りの実際の解凍やら再圧縮やら保存まわりに着手。
したら衝撃の事実が。
int WINAPI UnZipExtractMem(const HWND hWnd,LPCSTR szCmdLine……
(つд⊂)ゴシゴシ→(;゚ Д゚)HWNDってなんやっ!?
えーと、書庫開いたときに取得するHARCという書庫のハンドルを渡して、そこ経由で書庫内ファイルをメモリ上に展開する関数だと思ってたんですが、ハンドル指定がウィンドウハンドルになってる。
つまり、これ書庫全体をメモリ上に展開する機能だったのですね……。
欲しかったのは書庫内ファイルを単体でメモリ上に展開する機能だったのに……。
なので、結局書庫内ファイル単体解凍は、ファイルにしか書き出せない模様。
メモリ上に展開した画像ファイルなんかはそのままQImageに変換できるので、いちいちテンポラリにファイル書き出さなくて済む……筈だったのにっ。
むうう。
そこでまた方向転換。
基本的には、書庫内ファイルのファイル名のリネームや削除は問題無いとして(中のファイルが圧縮されてようが無かろうが、格納ファイルサイズ分取得して右から左にコピーするだけなので)書庫内の画像ファイルをどうこうするのに、書庫内ファイル単体で解凍する機能が欲しかったわけで。
そうなると、もとから非圧縮な書庫だと問題解決なんですよね。
そこでさらに、先日の日記でも触れた「UnifyZip」というソフト。
書庫形式をrar、lzh等からzipに統一、余分なフォルダ除去、書庫内ファイルのフィルタリング(気づいたら勝手に混入されてたりするサムネキャッシュのThumbs.dbとか除去)圧縮率も統一で、さらには書庫内のファイルの格納順の再ソートもやってくれる物なのですが、これって、コマンドラインツールなんですよね。なので、アプリから、処理するファイルのリストを登録して実行てのを丸投げできるんですよね。
そこで、ドラッグ&ドロップで登録された書庫を、そのリスト内で非圧縮でない書庫ファイルを全部、UnifyZipに送る。という機能を追加したら問題解決だなと。
それ以降の処理は、非圧縮な書庫のみ限定にして。
そもメインは画像系。それも大抵はjpgとかzipで圧縮しても98%とか99%にしかならない、サイズは変わらず読み込みだけは遅くなるという感じで、もともと圧縮する意味ない類の書庫ファイルをどうこうするのが主な目的なので。
そうなると後の処理が非常に楽ちん。
もともとunzip32.dllとかのアーカイバ系は、書庫内ファイルの個別処理には向いてない作りだし。
非圧縮ならバイナリで直接書庫ファイルを弄りほうだい、書庫内ファイルも取得し放題、編集も思いのまま。
これで、アーカイバの書庫内ハンドルつかって検索&処理という、なんだかこれ内部実装てきに速度とかどうなん? といまいち微妙かつ使いづらい(C言語ベースだし)ものも触らなくて済むなと。
そんな感じで、もうちょっと。
そろそろ実のところ飽きてきてます(ぉ
2016-08
14
05:44:04
もうちょっとで終わりそうだけど・・・
先週いっぱいで出来るかなと思ってた書庫回りのツール。
まだ終わらんち。
ちょっと一旦ソースのバックアップとったところで、そいえば昔、ステップ数とか計測するソフトとか使ってみたことあったっけ。
てな事を思い出し、計測してみる。
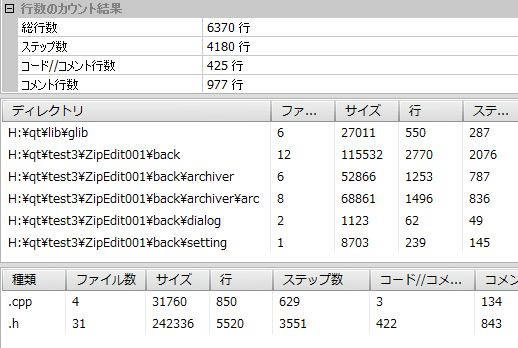
先々週ぐらいまでは、基礎実験というか、テストコードと、zipファイルのフォーマットのお勉強ばっかで、実際にちゃんと組み始めたのは先週ぐらいからなのですが……。部分部分はそのころのテストコードからコピペも多い物の……意外にいってるなぁ。だいたい4000ステップかぁ。サイズで言うと250KBくらい。
結構書いたな。
ちなみにQTだと、ウィンドウとかのウィジット系は、自動作成でcppとh(とui_xxxというxmlっぽいレイアウト用のなんか)が作られるのと、それらの中ではなんかマクロでいろいろとQTオブジェクト用の何かをやっているらしく、cppファイルを使わなくちゃいけないっぽいんですよね。
ここのところ、cppは一個しか使わない組み方(あとはhに全部実装も書くやり方)がメインなので、QTだとその辺ちょっとめんどくさい。
いまさら実装別けて書くのがもう面倒としか思えない。はやくc++もimnport実装されんかな……。
まあ、QTのオブジェクトじゃない物はみんなhだけで書けるのでそうしてますけど。
その結果がcpp=600ステップ h=3500ステップな内訳ですが、QTじゃなければcppはmain関数のみになるので、せいぜい数10ステップにしかならないと思われ。
しかし、GUIアプリっちゅーのはめんどくさいですね。
一個一個のコントロールの動作をちまちま書いていく地味な作業がかなり多い・・…。とくに今回のように、いろんな設定が必要なタイプのは特に。
でもまあ、QTだからかなり楽に書けてる部分もあるのでアレですけど。
とりあえず、あと数日中には終わらせたい所。
今のところ、設定のプリセット回り作ってて、設定をUIに流し込んだり、UIの情報をプリセットデータとしてファイルに読み書きしたり……設定の数が多いのでコード量が多くて大変ぽ。
それが終わったらあとはもう設定を元に、読み込んだ書庫を編集して書き出すだけなのであとちょっと。
しかし、unzip32とか7-zip32とか、もっと便利な物だと思ってたのにな。
一番欲しかったのは、いろんな圧縮形式でも解凍出来る部分だったんだけど。
今のところ、自前で読み込んだ場合、圧縮形式もデータの位置もサイズも取得出来てるのに、そこから何も出来ない……。いや出来ない事はないんだろうけど、自前で解凍ルーチン作るのは苦労が多すぎる……しかもzipの圧縮形式は同じzip形式と言っても一つではなく、様々な物があるので。
その辺のあたりをアーカイバに任せたたかったのだけども7-zip32の方は、個別にファイルを解凍する機能がなく、unzip32の方は、あるにはあるんだけど、統合アーカイバの作法による、独自のファイルハンドルを取得して、そのハンドル経由で、ファイル名検索かけてヒットしたファイルを解凍する。と言う感じだったりして。自前の方はファイル名をキーにしたハッシュテーブルで管理してるのですが、書庫内のハンドル経由の検索ってどのくらいのコストなんだろうか?
再圧縮無しでファイル名の変更とかやりたいので、自前で書庫内のそれぞれのファイルのヘッダの位置、圧縮ファイルの開始位置のオフセットを取得していたりするので、メモリ上に展開した圧縮ファイルを圧縮形式を指定したら解凍してくれる……みたいなのがあればベターだったんですけどね。
まあ、無いものはしようがない。
あと当初の予定から、やっぱダメじゃん、と方向転換した部分もあったり。
画像のリサイズとかの設定で、書庫内の画像ファイルのサイズとか取得したかったんですが、非圧縮の物なら大丈夫だけど、圧縮されてる奴はそも無理ジャン。って当たり前なことに気づくw
これも出来ない事はないんですが、それって、結局全ファイル解凍するだけの時間がかかるので、全ファイル分の画像のヘッダを読み込んで内容をリストに表示というのは時間掛かりすぎるぽ。画像のヘッダ部分のみ部分解凍なんて都合の良いこと出来ないよね……。
なので、非圧縮の場合のみ走査行って、圧縮されてる場合は、書庫内ファイルのリストを選択したときにそのファイルだけ解凍処理して画像の情報取得する感じにしてみたり。
で、そんなこんなで、当初は非圧縮で済む処理のものだけのツールと、再圧縮必要な処理でソフトを別けるつもりだったのですが、結局一本のソフトでまとめてやることに。
んで設定のグループを再圧縮が必要かどうかの点で二分する形にすればフラグ一つで処理も別けられるかなーというところもあったりして。
でもなんだかんだで結構なコード量になってるな。
もっと気楽にちょろっと作るつもりだったのにな……。
まだ終わらんち。
ちょっと一旦ソースのバックアップとったところで、そいえば昔、ステップ数とか計測するソフトとか使ってみたことあったっけ。
てな事を思い出し、計測してみる。
先々週ぐらいまでは、基礎実験というか、テストコードと、zipファイルのフォーマットのお勉強ばっかで、実際にちゃんと組み始めたのは先週ぐらいからなのですが……。部分部分はそのころのテストコードからコピペも多い物の……意外にいってるなぁ。だいたい4000ステップかぁ。サイズで言うと250KBくらい。
結構書いたな。
ちなみにQTだと、ウィンドウとかのウィジット系は、自動作成でcppとh(とui_xxxというxmlっぽいレイアウト用のなんか)が作られるのと、それらの中ではなんかマクロでいろいろとQTオブジェクト用の何かをやっているらしく、cppファイルを使わなくちゃいけないっぽいんですよね。
ここのところ、cppは一個しか使わない組み方(あとはhに全部実装も書くやり方)がメインなので、QTだとその辺ちょっとめんどくさい。
いまさら実装別けて書くのがもう面倒としか思えない。はやくc++もimnport実装されんかな……。
まあ、QTのオブジェクトじゃない物はみんなhだけで書けるのでそうしてますけど。
その結果がcpp=600ステップ h=3500ステップな内訳ですが、QTじゃなければcppはmain関数のみになるので、せいぜい数10ステップにしかならないと思われ。
しかし、GUIアプリっちゅーのはめんどくさいですね。
一個一個のコントロールの動作をちまちま書いていく地味な作業がかなり多い・・…。とくに今回のように、いろんな設定が必要なタイプのは特に。
でもまあ、QTだからかなり楽に書けてる部分もあるのでアレですけど。
とりあえず、あと数日中には終わらせたい所。
今のところ、設定のプリセット回り作ってて、設定をUIに流し込んだり、UIの情報をプリセットデータとしてファイルに読み書きしたり……設定の数が多いのでコード量が多くて大変ぽ。
それが終わったらあとはもう設定を元に、読み込んだ書庫を編集して書き出すだけなのであとちょっと。
しかし、unzip32とか7-zip32とか、もっと便利な物だと思ってたのにな。
一番欲しかったのは、いろんな圧縮形式でも解凍出来る部分だったんだけど。
今のところ、自前で読み込んだ場合、圧縮形式もデータの位置もサイズも取得出来てるのに、そこから何も出来ない……。いや出来ない事はないんだろうけど、自前で解凍ルーチン作るのは苦労が多すぎる……しかもzipの圧縮形式は同じzip形式と言っても一つではなく、様々な物があるので。
その辺のあたりをアーカイバに任せたたかったのだけども7-zip32の方は、個別にファイルを解凍する機能がなく、unzip32の方は、あるにはあるんだけど、統合アーカイバの作法による、独自のファイルハンドルを取得して、そのハンドル経由で、ファイル名検索かけてヒットしたファイルを解凍する。と言う感じだったりして。自前の方はファイル名をキーにしたハッシュテーブルで管理してるのですが、書庫内のハンドル経由の検索ってどのくらいのコストなんだろうか?
再圧縮無しでファイル名の変更とかやりたいので、自前で書庫内のそれぞれのファイルのヘッダの位置、圧縮ファイルの開始位置のオフセットを取得していたりするので、メモリ上に展開した圧縮ファイルを圧縮形式を指定したら解凍してくれる……みたいなのがあればベターだったんですけどね。
まあ、無いものはしようがない。
あと当初の予定から、やっぱダメじゃん、と方向転換した部分もあったり。
画像のリサイズとかの設定で、書庫内の画像ファイルのサイズとか取得したかったんですが、非圧縮の物なら大丈夫だけど、圧縮されてる奴はそも無理ジャン。って当たり前なことに気づくw
これも出来ない事はないんですが、それって、結局全ファイル解凍するだけの時間がかかるので、全ファイル分の画像のヘッダを読み込んで内容をリストに表示というのは時間掛かりすぎるぽ。画像のヘッダ部分のみ部分解凍なんて都合の良いこと出来ないよね……。
なので、非圧縮の場合のみ走査行って、圧縮されてる場合は、書庫内ファイルのリストを選択したときにそのファイルだけ解凍処理して画像の情報取得する感じにしてみたり。
で、そんなこんなで、当初は非圧縮で済む処理のものだけのツールと、再圧縮必要な処理でソフトを別けるつもりだったのですが、結局一本のソフトでまとめてやることに。
んで設定のグループを再圧縮が必要かどうかの点で二分する形にすればフラグ一つで処理も別けられるかなーというところもあったりして。
でもなんだかんだで結構なコード量になってるな。
もっと気楽にちょろっと作るつもりだったのにな……。
2016-08
10
05:34:42
四川式回鍋肉うまい
Cook Doの中華シリーズは良くつかうのですが、中でもコレが好きです。
ttp://www.ajinomoto.co.jp/cookdo/lineup/awase_033.html
普通の回鍋肉もあるのですが、こっちは四川式とのことで、ちょっとピリ辛。
日本式の回鍋肉だと豚肉の他にはキャベツとピーマンなのですが、本式の回鍋肉は、豚バラ肉茹でたの薄切りにしたのとニンニクの芽で作るのだそうな。(鉄鍋のジャン知識)その本式にちょっと近いのか、この四川式はピーマンは合わない感じ。パッケージ裏の説明にも、キャベツと長ネギが材料に上げられている。
冬なら鍋用な感じで長ネギもあったりするんですが、夏はあんまし無い。素麺とか冷や奴なんかで使う細いネギはあるけど。なので、タマネギで代用。(細いネギも入れるけど)
夏は辛いの食べて汗をかくのが良いですね。
……その後、ケツが火を噴きました(汚
辛い物食べ過ぎはダメですね……。
そんな感じでちまちまと。

トースト咥えたおなのこと、出会い頭にどっかーんなシチュで、相手が咥えてるものが、盗んできた鯛焼きではフラグ折れそうもないなーと言う感じな絵。
なんとなくセーラー着せてみました。
しかしやはり、ブランクの所為か、デッサン力ががた落ちです。
今回は夏コミ作業終わったからと行って、またブランク空けないようにしないとな……。
そんな感じで、時間分けて両立していくのが今のところ良い感じっぽいので、PGもモリモリ。
7-zip32.dllとunzip32.dll、結局抽象クラス作って継承で解決することに。
利用する予定のAPIはほとんどかぶってるので、コピペして名前変えるぐらいで出来。
んでもunzip32の方はGetLastError無いのね。
まあ、GetLastErrorの返値はただの数値で、対応するエラーコードはdefineされてるだけで、エラーコードの内容を文字列で取得しようと思うと、めんどくさい感じだったりするので、あんまし使わない……というか単に使い勝手が悪い感じなので省略なのかな。
統合アーカイバとかいって、APIを統一すると言いながらも、それぞれ制作者の個性が出てる感じで、微妙に混乱するぅ。
まあ、それ以前にみんなC言語ベースなので、その時点でかなりストレス溜まるんですけどね。今更生ポインタとか触りたくも無いし、全部大文字のdefine定数なんかも見たくも無いw
そんな感じで、アーカイバ回りの組み直しは終了。
そんで今は書庫ファイルを自前でバイナリでちまちま読んでいく所。
データ部(書庫内の圧縮ファイル)一つに対して、ヘッダが二つある仕様なのがうっとうしいw
しかもそのヘッダの中身は被ってるのが多いってのが何とも。
あと拡張データてのも、仕様がまちまちだったりするので、アレなフォーマットだなぁ。
とはいえ、自分で作った書庫を整理するのがメインなので、何処の誰がどんな環境でつくったのか判らない書庫にまで対応するような、汎用的なアーカイバみたいな物は端から作る気はないので、その点は気楽か。
というか
UnifyZip
ttp://kurima.sakura.ne.jp/
というフリーソフトが便利で、書庫形式をrar、lzh等からzipに統一、余分なフォルダ除去、書庫内ファイルのフィルタリング(気づいたら勝手に混入されてたりするサムネキャッシュのThumbs.dbとか除去)圧縮率も統一で、さらには書庫内のファイルの格納順の再ソートもやってくれる。
ほんとに便利~。
なので基本的には、まずUnifyZipにぶっ込んで、それから自前のツールでなんかする~ってパターンの運用になるので、その時点でへんなフォーマットのzipは想定しなくても良い感じだったりするぽ……。
というか、画像のリサイズのぞけばやりたいことの8割はこのツールで済んでしまうんですよね。
ただコンソールアプリなので、ファイル名の数値の桁揃えや正規表現とかでのリネーム前とリネーム結果を確認しながら……とか出来ない部分がちょっと不便だったりするので。
その辺を補うツールはやっぱほしいなと。
UnifyZipの機能をと同じ物を揃えて、単一のツールでみんな一括で……ってのが理想的ではあるんだけど、意外に7-zip32.dllとかunzip32.dllの機能って、かなり限定的で、細かい操作は全くできないんですよね。
もっとそういうことが出来る物だと思ってたんだけど、今回内部を精査してみたところ、やりたいことを実現するには独自に組まなきゃいけない部分ばかりなかんじに。
ファイルの走査辺りは、かなりレトロな実装で使い勝手はかなり悪い印象。
……コンソールアプリ向けだとまた違う印象なのかもだけど。
なんか半分愚痴だなこりゃ(ぉ
ttp://www.ajinomoto.co.jp/cookdo/lineup/awase_033.html
普通の回鍋肉もあるのですが、こっちは四川式とのことで、ちょっとピリ辛。
日本式の回鍋肉だと豚肉の他にはキャベツとピーマンなのですが、本式の回鍋肉は、豚バラ肉茹でたの薄切りにしたのとニンニクの芽で作るのだそうな。(鉄鍋のジャン知識)その本式にちょっと近いのか、この四川式はピーマンは合わない感じ。パッケージ裏の説明にも、キャベツと長ネギが材料に上げられている。
冬なら鍋用な感じで長ネギもあったりするんですが、夏はあんまし無い。素麺とか冷や奴なんかで使う細いネギはあるけど。なので、タマネギで代用。(細いネギも入れるけど)
夏は辛いの食べて汗をかくのが良いですね。
……その後、ケツが火を噴きました(汚
辛い物食べ過ぎはダメですね……。
そんな感じでちまちまと。
トースト咥えたおなのこと、出会い頭にどっかーんなシチュで、相手が咥えてるものが、盗んできた鯛焼きではフラグ折れそうもないなーと言う感じな絵。
なんとなくセーラー着せてみました。
しかしやはり、ブランクの所為か、デッサン力ががた落ちです。
今回は夏コミ作業終わったからと行って、またブランク空けないようにしないとな……。
そんな感じで、時間分けて両立していくのが今のところ良い感じっぽいので、PGもモリモリ。
7-zip32.dllとunzip32.dll、結局抽象クラス作って継承で解決することに。
利用する予定のAPIはほとんどかぶってるので、コピペして名前変えるぐらいで出来。
んでもunzip32の方はGetLastError無いのね。
まあ、GetLastErrorの返値はただの数値で、対応するエラーコードはdefineされてるだけで、エラーコードの内容を文字列で取得しようと思うと、めんどくさい感じだったりするので、あんまし使わない……というか単に使い勝手が悪い感じなので省略なのかな。
統合アーカイバとかいって、APIを統一すると言いながらも、それぞれ制作者の個性が出てる感じで、微妙に混乱するぅ。
まあ、それ以前にみんなC言語ベースなので、その時点でかなりストレス溜まるんですけどね。今更生ポインタとか触りたくも無いし、全部大文字のdefine定数なんかも見たくも無いw
そんな感じで、アーカイバ回りの組み直しは終了。
そんで今は書庫ファイルを自前でバイナリでちまちま読んでいく所。
データ部(書庫内の圧縮ファイル)一つに対して、ヘッダが二つある仕様なのがうっとうしいw
しかもそのヘッダの中身は被ってるのが多いってのが何とも。
あと拡張データてのも、仕様がまちまちだったりするので、アレなフォーマットだなぁ。
とはいえ、自分で作った書庫を整理するのがメインなので、何処の誰がどんな環境でつくったのか判らない書庫にまで対応するような、汎用的なアーカイバみたいな物は端から作る気はないので、その点は気楽か。
というか
UnifyZip
ttp://kurima.sakura.ne.jp/
というフリーソフトが便利で、書庫形式をrar、lzh等からzipに統一、余分なフォルダ除去、書庫内ファイルのフィルタリング(気づいたら勝手に混入されてたりするサムネキャッシュのThumbs.dbとか除去)圧縮率も統一で、さらには書庫内のファイルの格納順の再ソートもやってくれる。
ほんとに便利~。
なので基本的には、まずUnifyZipにぶっ込んで、それから自前のツールでなんかする~ってパターンの運用になるので、その時点でへんなフォーマットのzipは想定しなくても良い感じだったりするぽ……。
というか、画像のリサイズのぞけばやりたいことの8割はこのツールで済んでしまうんですよね。
ただコンソールアプリなので、ファイル名の数値の桁揃えや正規表現とかでのリネーム前とリネーム結果を確認しながら……とか出来ない部分がちょっと不便だったりするので。
その辺を補うツールはやっぱほしいなと。
UnifyZipの機能をと同じ物を揃えて、単一のツールでみんな一括で……ってのが理想的ではあるんだけど、意外に7-zip32.dllとかunzip32.dllの機能って、かなり限定的で、細かい操作は全くできないんですよね。
もっとそういうことが出来る物だと思ってたんだけど、今回内部を精査してみたところ、やりたいことを実現するには独自に組まなきゃいけない部分ばかりなかんじに。
ファイルの走査辺りは、かなりレトロな実装で使い勝手はかなり悪い印象。
……コンソールアプリ向けだとまた違う印象なのかもだけど。
なんか半分愚痴だなこりゃ(ぉ
2016-08
09
03:26:28
突撃したら道を間違えたてたでゴザル。
某氏の所の夏コミ原稿も終わったので、ちょっと隣町までお買い物。
道中、不思議な車が二台。
やたらとセンターラインギリギリの右側を走行する車。そのすぐ後ろには、逆に左側の線(車道外側線というらしい)の上に乗っかる勢いで左端を走る車。その後ろに私。
前がベタ左とベタ右なので、その二台を観てると、自分の位置があやふやになって変な感じw
てか、センターラインギリギリの車、交差点で右折待ちしてる車とぶつかりそうになって避けてるし……。
結構混み合う場所だったので、しばらくこの二台が前にいて、なんだか落ち着かなかったり。
その後、帰り道は別の広いいわゆる産業道路的な所通って帰ってきたのですが。
なんか見るからにドキュンがのってそうな軽トラが後ろから。
ルームミラーを観ると、運転手の顔が、これまた絵に描いたようなドキュン面。いやまあ、見た目で判断するのもどうかと……その後ウィンカーも出さずに蛇行運転しながら俺様運転で割り込みしまくって行きました。
見たまんまのすがすがしいまでのドキュンでした……。やっぱ顔に出るんだね、人格って。
そのあと、ふと前の車を見ると、前の車のドアミラーに可愛いわんこが映っている。
……? その位置だと運転席なんですが。わんこが運転してるの?
どうも小型犬で、運転席の窓側の所にわんこを置く棚というか籠というか、そういう感じの物があるらしい。
パッと見、普通に前を見据えてじっとしてるので、普通に運転手の様に見えたりで。
そんな感じで、たまに外に出ると、いろんな人もいるもんだなーとかおもたり。
んで、夏コミ原稿期間も終わって、平常運転に。
とりあえずPG再開。
相変わらずclangbackend.exeがソースファイルをロックして保存出来なくなる症状がでるのでイライラ。ググっても同じ症状な人いないのかな……うちだけの不具合なのだろうか……。
とりあえず、ノートンの監視を切ってみたりとかしてみても変わらず。ノートン先生が悪さしてるわけでもないっぽい。
なにげにここ最近急に誤爆削除の件数増えてる気がするぽ。自作のQT製のツールもいくつかdelされたし。なのでノートンが悪さしてるのかなと思ったんですけどね。ちがうっぽい。
なので結局clangコードモデルを一時的に利用停止中。
そうなると、autoとかで受け取ったオブジェクトのインテリセンス聞かなかったり、c++14辺りの機能つかうと、ビルドは出来てもqt creator上では波線やらでたりするので、うっとうしい。
むー。
そして、7-zip32.dllの関数とかもういろいろ面倒なのでドキュメントのAPI一覧をコピペしたやつをperlで全部一括でクラスのメンバとして使える形のc++コードに変換とかしてみたり。
win上で使えるperlの実行環境padreが便利でよいですね。
正規表現モリモリで実行するようなのって、レンタル鯖上で実行するのは、そうそう無いだろうけど万が一ハングったらとか思うと怖いのですが、ローカル鯖立てて実行とかもめんどくさいんですよね。大昔はサイトにうpするcgiもローカルでテストとかしていた時期もありましたが(遠い目)。でも、やっぱ文字コード回りは鬼門だなぁ。ソースコードもファイル出力もみんなutf-8で統一してるでの、実際の動作には問題でないのだけども、padre上の出力ウィンドウはがっつり文字化け。デバッグ出力的な使い方が出来ないので不便と言えば不便だ。ただまあ、そうしょっちゅう使う物でもないし、そもcgiの作成には向いてないしなこれ。今回のようにちょっとした込み入った文字列変換とかに使うぐらいだし。大抵結果はファイルに出力するのでそれほど困りはしないだろうけど。
んで、そこまでやってから気がついたのですが……。
7-zip32.dllって、書庫内のファイルの個別解凍とかできねえのな……。
そして、perlで出力したDLLのAPI関数を文字関係をQStringに書き換えたりとかちまちまやりながら中身見てたら……。
基本、目的からは、ほとんど使う事のなさそうな物ばかり……。それに、APIとして存在していても実際は、返値は「現時点ではエラー時以外は必ず 0 を返します」と、実質未実装な機能も結構目につくし……。
あれぇ? なんかすんごい時間ドブに捨ててた??w
とりあえず、やりたいことは
1.書庫内のファイル名のリネーム(正規表現置換、桁揃え)、不要なファイルとディレクトリの削除。それらを非解凍で。
2.書庫内画像ファイルの、フォーマット統一(すべてjpgとか)、リサイズ、書庫の圧縮率変更(無圧縮統一とか)
の二つで。
1の場合、結局自前で書庫ファイルをバイナリで開いて読み込んで、書庫内ファイルのデータサイズとか取得してそれらを参照しながら別の書庫をこれまたバイナリで書き込んで造るだけなので、今のところ全く7-zip32使う理由がない……。使えるとしたら書庫がほんとに書庫なのかのチェックぐらいか。でもunzip32にも同様の機能あるんだよな。
んで、2の時、書庫内ファイルの画像のフォーマットとかサイズとかをリスト表示したかったんだけど、非圧縮の場合はそのままの形で画像ファイルが存在するので、直接画像のヘッダを読めるのだけど、圧縮されてるものは解凍しなければならない。
んで、zipの面倒なところは、その圧縮のアルゴリズムが多種多様に存在すること。
なので、その辺を既存の物を使わせてもらおうと思っていたのだけども……。
その肝心なところが7-zip32には存在しない……。
unzip32の方見てみたら普通にUnZipExtract、さらにはUnZipExtractMemという、メモリ上に書庫の中の圧縮ファイルを解凍するという、一番欲しかった物がある。
うーん。
一応リネーム機能のあるオープンソースなアーカイバのソースコード弄ってたときに見た、各アーカイバの使用優先順位設定のところで、unzip32のが7-zip32より上位にあったんだよなぁ。
なにげに圧縮率とか対応書庫の種類とかから、漠然と7-zip32のが良い物だと思い込んでいてunzip32の上位互換的なイメージあったんだけどそこに大きな誤謬があったのかなーとか。
一括で圧縮解凍の用途のみならそれも間違いではないのかもだけど、書庫内ファイルを個別にどうこうするには向いてない物だったとは……。
1の場合、zip書庫として正しい物であれば、圧縮方法は関係無いんですよね。単にファイル名変更して、データヘッダのファイル名の長さのフィールド値変更して。あとはヘッダ内のファイルサイズ分新しい書庫ファイルにそのままコピーするだけなので。
unzip32でまず書庫ファイルチェックして、漏れたら次は7-zip32でチェック……まんまオープンソースの奴の処理と同じやぁ。
優先順位の件といい、そういうことだったのかといろいろと腑に落ちる。
なんか変な回り道した所為でか、結構ソースコードとかソースのファイル名とか混迷してきたので、また1からリライトするか。
7-zip32てunzip32の上位互換みたいな物だと勘違いしていたので、複数のアーカイバ対応する必要もないし、zip決め打ちなら7-zip32オンリーで良いジャンと、アーカイバ回りのクラスとかSevenZipなんとかーとか名前つけちゃってたんですよね……w
んでもまあ、ようやくzip書庫ファイル回りの全体像が把握できてきたぽ。
とりあえず今週中には終わるかなぁ。
他にもいろいろとやりたいことは山積してることだし。
道中、不思議な車が二台。
やたらとセンターラインギリギリの右側を走行する車。そのすぐ後ろには、逆に左側の線(車道外側線というらしい)の上に乗っかる勢いで左端を走る車。その後ろに私。
前がベタ左とベタ右なので、その二台を観てると、自分の位置があやふやになって変な感じw
てか、センターラインギリギリの車、交差点で右折待ちしてる車とぶつかりそうになって避けてるし……。
結構混み合う場所だったので、しばらくこの二台が前にいて、なんだか落ち着かなかったり。
その後、帰り道は別の広いいわゆる産業道路的な所通って帰ってきたのですが。
なんか見るからにドキュンがのってそうな軽トラが後ろから。
ルームミラーを観ると、運転手の顔が、これまた絵に描いたようなドキュン面。いやまあ、見た目で判断するのもどうかと……その後ウィンカーも出さずに蛇行運転しながら俺様運転で割り込みしまくって行きました。
見たまんまのすがすがしいまでのドキュンでした……。やっぱ顔に出るんだね、人格って。
そのあと、ふと前の車を見ると、前の車のドアミラーに可愛いわんこが映っている。
……? その位置だと運転席なんですが。わんこが運転してるの?
どうも小型犬で、運転席の窓側の所にわんこを置く棚というか籠というか、そういう感じの物があるらしい。
パッと見、普通に前を見据えてじっとしてるので、普通に運転手の様に見えたりで。
そんな感じで、たまに外に出ると、いろんな人もいるもんだなーとかおもたり。
んで、夏コミ原稿期間も終わって、平常運転に。
とりあえずPG再開。
相変わらずclangbackend.exeがソースファイルをロックして保存出来なくなる症状がでるのでイライラ。ググっても同じ症状な人いないのかな……うちだけの不具合なのだろうか……。
とりあえず、ノートンの監視を切ってみたりとかしてみても変わらず。ノートン先生が悪さしてるわけでもないっぽい。
なにげにここ最近急に誤爆削除の件数増えてる気がするぽ。自作のQT製のツールもいくつかdelされたし。なのでノートンが悪さしてるのかなと思ったんですけどね。ちがうっぽい。
なので結局clangコードモデルを一時的に利用停止中。
そうなると、autoとかで受け取ったオブジェクトのインテリセンス聞かなかったり、c++14辺りの機能つかうと、ビルドは出来てもqt creator上では波線やらでたりするので、うっとうしい。
むー。
そして、7-zip32.dllの関数とかもういろいろ面倒なのでドキュメントのAPI一覧をコピペしたやつをperlで全部一括でクラスのメンバとして使える形のc++コードに変換とかしてみたり。
win上で使えるperlの実行環境padreが便利でよいですね。
正規表現モリモリで実行するようなのって、レンタル鯖上で実行するのは、そうそう無いだろうけど万が一ハングったらとか思うと怖いのですが、ローカル鯖立てて実行とかもめんどくさいんですよね。大昔はサイトにうpするcgiもローカルでテストとかしていた時期もありましたが(遠い目)。でも、やっぱ文字コード回りは鬼門だなぁ。ソースコードもファイル出力もみんなutf-8で統一してるでの、実際の動作には問題でないのだけども、padre上の出力ウィンドウはがっつり文字化け。デバッグ出力的な使い方が出来ないので不便と言えば不便だ。ただまあ、そうしょっちゅう使う物でもないし、そもcgiの作成には向いてないしなこれ。今回のようにちょっとした込み入った文字列変換とかに使うぐらいだし。大抵結果はファイルに出力するのでそれほど困りはしないだろうけど。
んで、そこまでやってから気がついたのですが……。
7-zip32.dllって、書庫内のファイルの個別解凍とかできねえのな……。
そして、perlで出力したDLLのAPI関数を文字関係をQStringに書き換えたりとかちまちまやりながら中身見てたら……。
基本、目的からは、ほとんど使う事のなさそうな物ばかり……。それに、APIとして存在していても実際は、返値は「現時点ではエラー時以外は必ず 0 を返します」と、実質未実装な機能も結構目につくし……。
あれぇ? なんかすんごい時間ドブに捨ててた??w
とりあえず、やりたいことは
1.書庫内のファイル名のリネーム(正規表現置換、桁揃え)、不要なファイルとディレクトリの削除。それらを非解凍で。
2.書庫内画像ファイルの、フォーマット統一(すべてjpgとか)、リサイズ、書庫の圧縮率変更(無圧縮統一とか)
の二つで。
1の場合、結局自前で書庫ファイルをバイナリで開いて読み込んで、書庫内ファイルのデータサイズとか取得してそれらを参照しながら別の書庫をこれまたバイナリで書き込んで造るだけなので、今のところ全く7-zip32使う理由がない……。使えるとしたら書庫がほんとに書庫なのかのチェックぐらいか。でもunzip32にも同様の機能あるんだよな。
んで、2の時、書庫内ファイルの画像のフォーマットとかサイズとかをリスト表示したかったんだけど、非圧縮の場合はそのままの形で画像ファイルが存在するので、直接画像のヘッダを読めるのだけど、圧縮されてるものは解凍しなければならない。
んで、zipの面倒なところは、その圧縮のアルゴリズムが多種多様に存在すること。
なので、その辺を既存の物を使わせてもらおうと思っていたのだけども……。
その肝心なところが7-zip32には存在しない……。
unzip32の方見てみたら普通にUnZipExtract、さらにはUnZipExtractMemという、メモリ上に書庫の中の圧縮ファイルを解凍するという、一番欲しかった物がある。
うーん。
一応リネーム機能のあるオープンソースなアーカイバのソースコード弄ってたときに見た、各アーカイバの使用優先順位設定のところで、unzip32のが7-zip32より上位にあったんだよなぁ。
なにげに圧縮率とか対応書庫の種類とかから、漠然と7-zip32のが良い物だと思い込んでいてunzip32の上位互換的なイメージあったんだけどそこに大きな誤謬があったのかなーとか。
一括で圧縮解凍の用途のみならそれも間違いではないのかもだけど、書庫内ファイルを個別にどうこうするには向いてない物だったとは……。
1の場合、zip書庫として正しい物であれば、圧縮方法は関係無いんですよね。単にファイル名変更して、データヘッダのファイル名の長さのフィールド値変更して。あとはヘッダ内のファイルサイズ分新しい書庫ファイルにそのままコピーするだけなので。
unzip32でまず書庫ファイルチェックして、漏れたら次は7-zip32でチェック……まんまオープンソースの奴の処理と同じやぁ。
優先順位の件といい、そういうことだったのかといろいろと腑に落ちる。
なんか変な回り道した所為でか、結構ソースコードとかソースのファイル名とか混迷してきたので、また1からリライトするか。
7-zip32てunzip32の上位互換みたいな物だと勘違いしていたので、複数のアーカイバ対応する必要もないし、zip決め打ちなら7-zip32オンリーで良いジャンと、アーカイバ回りのクラスとかSevenZipなんとかーとか名前つけちゃってたんですよね……w
んでもまあ、ようやくzip書庫ファイル回りの全体像が把握できてきたぽ。
とりあえず今週中には終わるかなぁ。
他にもいろいろとやりたいことは山積してることだし。
Sun
Mon
Tue
Wed
Thu
Fri
Sat
01
02
03
04
05
06
07
08
09
■
■
突撃したら道を間違えたてたでゴザル。
10
■
■
四川式回鍋肉うまい
11
[山の日]
12
13
14
■
■
もうちょっとで終わりそうだけど・・・
15
16
17
■
■
見間違え……
18
19
■
■
一難去ってまた一難……
20
21
22
23
■
■
ずるずる
24
25
26
27
28
■
■
ようやく一段落
29
■
■
まだまだ知らないことばかり
30
31
total:2206903 t:632 y:485
■記事タイトル■
■年度別リスト■
2026年
2026年12月(0)2026年11月(0)
2026年10月(0)
2026年09月(0)
2026年08月(0)
2026年07月(0)
2026年06月(0)
2026年05月(0)
2026年04月(0)
2026年03月(1)
2026年02月(3)
2026年01月(3)
2025年
2025年12月(1)2025年11月(1)
2025年10月(2)
2025年09月(5)
2025年08月(3)
2025年07月(1)
2025年06月(2)
2025年05月(1)
2025年04月(2)
2025年03月(3)
2025年02月(8)
2025年01月(3)
2024年
2024年12月(1)2024年11月(2)
2024年10月(1)
2024年09月(2)
2024年08月(1)
2024年07月(1)
2024年06月(5)
2024年05月(2)
2024年04月(1)
2024年03月(6)
2024年02月(4)
2024年01月(3)
2023年
2023年12月(3)2023年11月(1)
2023年10月(2)
2023年09月(3)
2023年08月(3)
2023年07月(3)
2023年06月(7)
2023年05月(8)
2023年04月(2)
2023年03月(1)
2023年02月(2)
2023年01月(3)
2022年
2022年12月(4)2022年11月(3)
2022年10月(1)
2022年09月(3)
2022年08月(3)
2022年07月(2)
2022年06月(1)
2022年05月(3)
2022年04月(2)
2022年03月(2)
2022年02月(1)
2022年01月(6)
2021年
2021年12月(8)2021年11月(3)
2021年10月(4)
2021年09月(6)
2021年08月(2)
2021年07月(1)
2021年06月(3)
2021年05月(2)
2021年04月(2)
2021年03月(3)
2021年02月(1)
2021年01月(4)
2020年
2020年12月(3)2020年11月(7)
2020年10月(2)
2020年09月(3)
2020年08月(1)
2020年07月(3)
2020年06月(7)
2020年05月(5)
2020年04月(8)
2020年03月(4)
2020年02月(2)
2020年01月(4)
2019年
2019年12月(1)2019年11月(1)
2019年10月(2)
2019年09月(1)
2019年08月(3)
2019年07月(2)
2019年06月(2)
2019年05月(2)
2019年04月(4)
2019年03月(1)
2019年02月(7)
2019年01月(1)
2018年
2018年12月(1)2018年11月(1)
2018年10月(5)
2018年09月(1)
2018年08月(5)
2018年07月(1)
2018年06月(1)
2018年05月(1)
2018年04月(2)
2018年03月(2)
2018年02月(1)
2018年01月(1)
2017年
2017年12月(2)2017年11月(1)
2017年10月(2)
2017年09月(5)
2017年08月(8)
2017年07月(2)
2017年06月(1)
2017年05月(1)
2017年04月(3)
2017年03月(5)
2017年02月(7)
2017年01月(8)
2016年
2016年12月(7)2016年11月(2)
2016年10月(3)
2016年09月(7)
2016年08月(8)
2016年07月(10)
2016年06月(17)
2016年05月(6)
2016年04月(8)
2016年03月(10)
2016年02月(5)
2016年01月(10)
2015年
2015年12月(7)2015年11月(7)
2015年10月(13)
2015年09月(7)
2015年08月(7)
2015年07月(5)
2015年06月(4)
2015年05月(5)
2015年04月(2)
2015年03月(4)
2015年02月(1)
2015年01月(7)
2014年
2014年12月(12)2014年11月(8)
2014年10月(4)
2014年09月(6)
2014年08月(7)
2014年07月(4)
2014年06月(2)
2014年05月(5)
2014年04月(4)
2014年03月(8)
2014年02月(4)
2014年01月(8)
2013年
2013年12月(15)2013年11月(8)
2013年10月(3)
2013年09月(3)
2013年08月(8)
2013年07月(0)
2013年06月(0)
2013年05月(0)
2013年04月(0)
2013年03月(0)
2013年02月(0)
2013年01月(0)
■レス履歴■
■ファイル抽出■
■ワード検索■
堕天使の煉獄
https://rengoku.sakura.ne.jp
管理人
織田霧さくら(oda-x)
E-mail (■を@に)
oda-x■rengoku.sakura.ne.jp